Streamlining NGS: A Guide to the AmpliSeq for Illumina Direct FFPE DNA Protocol Without Purification
This article provides a comprehensive overview of the AmpliSeq for Illumina Direct FFPE DNA protocol, a targeted next-generation sequencing (NGS) approach that enables library construction from formalin-fixed paraffin-embedded (FFPE) tissues...
Streamlining NGS: A Guide to the AmpliSeq for Illumina Direct FFPE DNA Protocol Without Purification
Abstract
This article provides a comprehensive overview of the AmpliSeq for Illumina Direct FFPE DNA protocol, a targeted next-generation sequencing (NGS) approach that enables library construction from formalin-fixed paraffin-embedded (FFPE) tissues without the need for deparaffinization or DNA purification. Tailored for researchers and drug development professionals, we explore the foundational principles of this method, detail the step-by-step workflow and its integration with various AmpliSeq panels, address common troubleshooting and optimization strategies for challenging samples, and present validation data and comparative analyses with other techniques. The protocol significantly reduces hands-on time and preserves precious samples, facilitating robust genomic research from degraded FFPE material.
Understanding the AmpliSeq Direct FFPE DNA Protocol: Principles and Advantages
Formalin-Fixed Paraffin-Embedded (FFPE) samples represent an invaluable resource in biomedical research and clinical diagnostics, with vast archives of preserved tissues available for retrospective analysis [1] [2]. These samples offer a window into historical pathology and molecular signatures, particularly for cancer genomics and biomarker discovery [3]. However, the very fixation and storage methods that make them durable also introduce significant challenges for next-generation sequencing (NGS). DNA extracted from FFPE samples is often degraded, cross-linked, and chemically modified, creating substantial obstacles for reliable genomic analysis [3] [1]. Understanding these challenges and implementing robust mitigation strategies is crucial for leveraging the full potential of FFPE samples in research and clinical applications, particularly when using targeted approaches like the AmpliSeq for Illumina Direct FFPE DNA protocol.
Core Challenges: Degradation and Impurities
The process of formalin fixation and paraffin embedding introduces multiple types of DNA damage that compromise sequencing quality and variant calling accuracy.
Chemical Degradation Mechanisms
Formalin fixation triggers several chemical alteration pathways that damage DNA integrity:
- Cross-linking: Formaldehyde reacts with DNA and proteins to form covalent methylene bridges, creating DNA-DNA, DNA-RNA, and DNA-protein crosslinks that inhibit enzymatic manipulation [3] [4].
- Fragmentation: Formaldehyde fixation accelerates cleavage of glycosidic bonds, generating apurinic/apyrimidinic (AP) sites that lead to DNA backbone fragmentation [3]. Under acidic conditions (from unbuffered formalin), this process intensifies through hydrolysis of protonated purines [3].
- Base Alterations: Chemical addition reactions of formaldehyde to nucleophilic groups of DNA bases result in modified species with altered base pairing abilities [3].
- Deamination: Spontaneous deamination of cytosine to uracil represents the most frequently encountered chemical alteration in FFPE-DNA, leading to C>T/G>A base substitutions during sequencing [3] [2]. When cytosine is methylated (5-methylcytosine), deamination produces thymine, causing the same artifactual substitutions [3].
Impact of Storage Time on DNA Integrity
Long-term storage of FFPE samples significantly exacerbates DNA degradation, as demonstrated by quantitative studies:
Table 1: Age-Related DNA Degradation in FFPE Samples
| Storage Time (Years) | Q-score (Q129/Q41) | DNA Fragmentation Level | Amplification Efficiency |
|---|---|---|---|
| 0.5 | 85.2% | Low | High |
| 3 | 45.1% | Moderate | Reduced |
| 6 | 32.8% | High | Significantly Reduced |
| 9 | 28.3% | High | Significantly Reduced |
| 12 | 15.6% | Severe | Severely Impaired |
Research has demonstrated that aging significantly contributes to DNA fragmentation, with notable degradation observed between 0.5 and 3 years of storage, and further deterioration after 9-12 years [5]. The Q-score, which represents the quantitative value ratio of different PCR product sizes (Q129/Q41), decreases substantially with storage time, indicating progressive fragmentation that limits the amplifiable DNA template [5].
Consequences for NGS Applications
The chemical modifications in FFPE-DNA propagate into downstream NGS applications with several detrimental effects:
- Increased Sequencing Artefacts: FFPE-DNA exhibits a marked increase in C>T/G>A transitions (up to 7-fold compared to fresh-frozen tissue), along with C>A/G>T changes from base oxidation [3]. These artefacts can reach high allele frequencies (>10%), particularly in regions of low sequencing coverage [3].
- Reduced Library Complexity: Crosslinks and AP sites can block DNA polymerase during amplification, leading to dropout of genomic regions and reduced diversity of functional sequencing library molecules [3].
- Coverage Irregularities: Compared to frozen samples, NGS data from FFPE samples shows smaller library insert sizes, greater coverage variability, and higher sequence duplication ratios [3] [4].
- False Positive Variants: The combination of cytosine deamination artefacts within regions of diminished true sequences leads to high variant allele frequencies (VAF) of these false signals, potentially resulting in misinterpretation of mutational status [3] [2].
Quantitative Analysis of FFPE DNA Quality
Systematic evaluation of DNA extracted from FFPE tissues reveals substantial quality variations that directly impact NGS performance.
Extraction Method Comparisons
The choice of DNA extraction method significantly influences the quantity and quality of recovered nucleic acids:
Table 2: DNA Extraction Method Comparison for FFPE Samples
| Extraction Method | Principle | DNA Yield | Purity (A260/280) | Degree of Fragmentation | Best Application |
|---|---|---|---|---|---|
| Silica-Membrane (QIAamp) | DNA binding to silica membrane | Lower | Higher (1.8-2.0) | Less fragmented | Variant detection, clinical diagnostics |
| Total Tissue Collection (WaxFree) | Total DNA collection with inhibitor removal | Higher | Lower (<1.8) | More fragmented | Maximum DNA recovery, low-input applications |
| Proteinase K/Phenol-Chloroform | Digestion and organic extraction | Variable | Variable | Highly variable | Historical samples, research use |
Comparative studies demonstrate that the silica-binding method (QIAamp) yields less fragmented DNA with higher purity, while the total tissue collection approach (WaxFree) provides higher overall yields but with more contaminants and fragmentation [5]. The silica-membrane method is therefore generally preferred for clinical NGS applications where variant calling accuracy is paramount.
Quality Metrics and Their Interpretation
Effective quality control of FFPE-DNA requires multiple complementary assessment methods:
- UV Spectrophotometry: The A260/280 ratio indicates protein contamination, with optimal values ranging from 1.8-2.0 [5]. The silica-membrane method typically yields ratios of 1.9, while total tissue collection methods show lower values of approximately 1.6, indicating higher contaminant levels [5].
- Fluorometric Quantification: Dye-based methods (e.g., Qubit Fluorometer) provide accurate DNA concentration measurements by specifically binding to double-stranded DNA, avoiding overestimation from contaminants [5].
- Fragment Analysis: The Q-score system, based on quantitative PCR with different amplicon sizes (41bp, 129bp, 305bp), objectively measures DNA fragmentation levels [5]. A decreasing Q129/Q41 ratio indicates progressive fragmentation that directly correlates with reduced amplification efficiency for longer targets.
- Multiplex PCR Assay: Quality assessment using amplicons of varying lengths (105bp, 239bp, 299bp, 411bp) categorizes samples as high quality (≥299bp amplifiable) or poor quality (only 105bp amplifiable) [4].
AmpliSeq for Illumina Direct FFPE DNA Protocol
The AmpliSeq for Illumina technology provides a targeted sequencing approach specifically designed to overcome challenges associated with FFPE samples, enabling reliable variant detection even from compromised DNA.
AmpliSeq for Illumina employs an ultrahigh multiplex PCR approach to amplify specific genomic regions of interest, offering several advantages for FFPE-DNA analysis:
- Low DNA Input Requirements: The protocol requires only 1-100 ng of input DNA, with 10 ng recommended per pool, making it suitable for precious FFPE samples with limited yield [6].
- Short Amplicon Design: By targeting smaller genomic regions (amplicons ranging from 12 to 12,288), the technology effectively amplifies fragmented DNA templates common in FFPE specimens [6] [7].
- Robust Performance with Degraded Samples: The multiplex PCR chemistry achieves unmatched data quality even from low-quality starting materials such as FFPE tissues [6].
- Streamlined Workflow: Library preparation requires approximately 5 hours with only 1.5 hours of hands-on time, enabling rapid processing of clinical samples [6].
Comprehensive Workflow for FFPE Samples
The complete protocol for implementing AmpliSeq for Illumina with FFPE samples involves coordinated wet-lab and computational steps:
Detailed Experimental Protocol
Pre-Analytical Quality Control
- Sample Selection: Identify FFPE blocks with optimal tumor content through pathologist review of hematoxylin and eosin (H&E) stained sections [8].
- Macrodissection: For heterogeneous tissues, perform precision macrodissection to enrich target cell populations while excluding confounding elements [8].
- DNA Extraction: Extract DNA using silica-membrane methods (e.g., QIAamp DNA FFPE Tissue kit) following manufacturer's protocols [5].
- Quality Assessment:
- Quantify DNA using fluorometric methods (e.g., Qubit dsDNA HS Assay)
- Assess fragmentation via qPCR with multiple amplicon sizes (41bp, 129bp, 305bp)
- Calculate Q-score as Q129/Q41 ratio; samples with Q-score <5% require special consideration [3]
DNA Repair Treatment (Optional but Recommended)
For samples with significant damage or older archives, implement DNA repair prior to library preparation:
- Repair Reagent Formulation: Utilize enzyme mixtures containing:
- Incubation Conditions: Incubate 10-100ng FFPE-DNA with repair enzymes at specific temperatures according to manufacturer specifications (typically 37°C for 30 minutes, then 4°C hold) [1].
- Purification: Clean repaired DNA using magnetic beads or column-based purification.
Library Preparation with AmpliSeq for Illumina
Multiplex PCR Amplification:
- Combine repaired DNA with AmpliSeq Custom DNA Panel primers
- Perform PCR amplification with cycling conditions optimized for FFPE-DNA
- The ultrahigh multiplex PCR simultaneously amplifies hundreds to thousands of targets [7]
Partial Digestion: Treat amplicons with FuPa reagent to partially digest primers and phosphorylate ends.
Adapter Ligation: Add Illumina-specific barcoded adapters to enable sample multiplexing.
Library Amplification: Perform limited-cycle PCR to enrich for adapter-ligated fragments.
Library Purification: Clean up libraries using Agencourt AMPure XP beads.
Quality Control: Assess library size distribution and quantity using Agilent Bioanalyzer or TapeStation.
Sequencing and Data Analysis
- Pooling and Normalization: Combine barcoded libraries in equimolar ratios for multiplexed sequencing.
- Sequencing: Load pooled libraries onto Illumina platforms (iSeq, MiSeq, NextSeq 1000/2000) using version 3 chemistry for paired-end 101bp reads [4].
- Bioinformatic Processing:
- Demultiplex reads and align to reference genome (hg19)
- Perform duplicate marking and base quality recalibration
- Implement FFPE-specific artefact filtering:
- Remove C>T/G>A transitions in low-complexity regions
- Filter variants with strand bias
- Exclude low-quality calls in contexts of low coverage [3]
- Variant Calling: Use validated algorithms for SNV, indel, CNV, and fusion detection.
Research Reagent Solutions
Successful NGS from FFPE samples requires specialized reagents to address unique challenges posed by fixed tissues.
Table 3: Essential Research Reagents for FFPE-DNA NGS
| Reagent Category | Product Examples | Primary Function | Application Notes |
|---|---|---|---|
| DNA Extraction Kits | QIAamp DNA FFPE Tissue Kit | Silica-membrane based DNA purification with crosslink reversal | Higher purity DNA, optimal for clinical variant detection [5] |
| DNA Repair Reagents | Hieff NGS FFPE DNA Repair Reagent | Enzyme mixture repairing deamination, nicks, oxidized bases | Critical for low-quality samples; improves library yield [1] |
| Library Preparation Kits | AmpliSeq for Illumina Direct FFPE DNA | Targeted multiplex PCR for degraded DNA | Requires 1-100 ng input; optimized for FFPE fragments [6] |
| Artefact Suppression Reagents | GeneRead DNA FFPE Kit | Enzymatic removal of deaminated cytosines | Reduces false positive C>T/G>A mutations [2] |
| Target Enrichment Panels | AmpliSeq Custom DNA Panels | Primer pools for specific genomic regions | Flexible design (12-12,288 amplicons); covers genes of interest [6] |
| Quantification Assays | Qubit dsDNA HS Assay | Fluorometric DNA quantification | Accurate concentration measurement of fragmented DNA [5] |
The challenges posed by FFPE samples for NGS applications are significant but manageable through integrated methodological approaches. The combination of appropriate DNA extraction methods, targeted repair techniques, optimized library preparation protocols, and bioinformatic correction strategies enables reliable genomic analysis even from highly degraded archival material.
The AmpliSeq for Illumina Direct FFPE DNA protocol represents a particularly effective solution for clinical and research applications, demonstrating that routine processing of FFPE samples has a detectable but manageable effect on NGS data [4]. Studies have shown that with proper optimization, FFPE and fresh-frozen samples can achieve concordances of >99.99% in base calls, with 96.8% agreement in single-nucleotide variant detection [4].
Future directions in FFPE-NGS methodology will likely focus on enhanced repair enzymes capable of addressing a broader spectrum of DNA lesions, improved bioinformatic tools for artefact identification and removal, and integrated workflows that further minimize input requirements while maximizing data quality. As these technologies evolve, the vast archives of FFPE specimens will continue to yield invaluable insights for cancer research, biomarker discovery, and clinical diagnostics.
The analysis of formalin-fixed paraffin-embedded (FFPE) tissues represents a cornerstone of clinical research and diagnostics, with vast archives of these samples constituting an invaluable resource for biomedical studies. [9] However, traditional DNA extraction methods from FFPE material present significant challenges, including DNA fragmentation, cross-linking, and the introduction of sequence artifacts that compromise downstream genetic analyses. [9] [10] These limitations are primarily attributed to the formalin fixation process, which creates chemical crosslinks that diminish DNA quality and complicate extraction procedures. [10] We present a transformative approach that eliminates both deparaffinization and DNA purification steps, enabling direct access to amplifiable DNA from FFPE tissues for next-generation sequencing (NGS) applications.
The Innovation: Direct FFPE DNA Processing
Principle and Mechanism
The core innovation bypasses traditional sample preparation hurdles through a simplified, efficient workflow that converts FFPE tissue sections directly into DNA suitable for amplification without intermediate purification steps. This method leverages specialized reagents that simultaneously address paraffin incorporation and crosslink reversal in a single tube, dramatically reducing processing time and hands-on intervention while minimizing sample loss. [11]
Table 1: Key Advantages of the Direct FFPE DNA Protocol
| Parameter | Traditional FFPE DNA Extraction | Direct FFPE DNA Protocol |
|---|---|---|
| Processing Time | Several hours to overnight digestion [12] | ~30 minutes total, 10 minutes hands-on [11] |
| Deparaffinization | Required (organic solvents or mineral oil) [9] [12] | Not required [11] |
| DNA Purification | Column-based or bead-based purification [9] | Not required [11] |
| Sample Loss | Significant due to multiple transfer steps | Minimal (single-tube protocol) |
| Input Material | Often requires multiple sections | Suitable for limited DNA samples |
Experimental Protocol and Workflow
Materials and Reagents:
- Ion AmpliSeq Direct FFPE DNA Kit (Transfer Solution, Direct Reagent) [11]
- FFPE tissue sections (up to 10 μm thick mounted on glass slides)
- PCR tubes or 96-well plates
- Piper tips and micro-scalpels
- Thermal cycler or heating block
Step-by-Step Procedure:
Sample Collection: Identify the area of interest on the FFPE tissue section. Apply Transfer Solution to the region and scrape the tissue using a pipette tip or micro-scalpel. [11]
Sample Transfer: Transfer the tissue scrapings directly into a PCR tube or 96-well plate. The Transfer Solution facilitates easy movement of the sample without compromising subsequent reactions.
Direct Incubation: Add the provided Direct Reagent to the sample tube. The proprietary formulation reverses formalin-induced crosslinks and neutralizes PCR inhibitors present in the tissue matrix. [11]
Thermal Treatment: Incubate the sample at 65°C for 15 minutes. This single heating step simultaneously completes reverse-crosslinking and prepares the DNA for amplification. [11]
Quality Assessment (Optional): The prepared DNA can be quantified using high-sensitivity DNA quantification methods such as the Qubit HS DNA Quantitation Kit, though this step is not mandatory for proceeding to library preparation. [11]
Library Preparation: Use the processed DNA directly in the Ion AmpliSeq library preparation protocol with as little as 1 ng input DNA. The kit includes optional Uracil-D-glycosylase treatment to remove deaminated cytosines, addressing a common artifact in FFPE-derived DNA. [11]
Performance and Validation
Quantitative Performance Metrics
The direct FFPE DNA protocol demonstrates equivalent or superior performance compared to traditional extraction methods, particularly in critical parameters that impact next-generation sequencing success.
Table 2: Performance Comparison of DNA Extraction Methods
| Method | DNA Yield | Processing Time | Hands-on Time | Sequencing Library Yield | Application |
|---|---|---|---|---|---|
| Direct FFPE Protocol | Suitable for limited samples [11] | 30 minutes [11] | 10 minutes [11] | Compatible with 1 ng input [11] | Targeted sequencing |
| HiTE Method | 3× higher than commercial kits [9] | Several hours | Significant | 3× higher library yield [9] | WGS & targeted sequencing |
| Commercial Kits (Traditional) | Variable, often low [9] | 2.5+ hours [12] | 30+ minutes | Standard | General purpose |
| Solvent-Based Methods | Moderate | Several hours | Significant | Variable with fragmentation | Historical standard |
Methodological Advantages in Research Context
The bypass method demonstrates particular utility in addressing longstanding challenges in FFPE-based research:
Minimized DNA Damage: By eliminating harsh deparaffinization solvents like xylene and reducing processing time, the protocol better preserves DNA integrity. [10] [12]
Protocol Standardization: The simplified workflow reduces technical variability between experiments and operators, enhancing reproducibility for large-scale studies. [10]
Resource Efficiency: The minimal hands-on time (10 minutes) and rapid turnaround (30 minutes total) enable higher throughput processing with existing laboratory resources. [11]
Compatibility with Automation: The single-tube, two-step protocol is readily adaptable to automated liquid handling systems, facilitating integration into high-throughput screening pipelines. [11]
Research Reagent Solutions
Table 3: Essential Research Reagents for Direct FFPE DNA Protocols
| Reagent / Kit | Manufacturer | Primary Function | Application Specificity |
|---|---|---|---|
| Ion AmpliSeq Direct FFPE DNA Kit | Thermo Fisher Scientific [11] | Direct processing of FFPE tissues without purification | AmpliSeq library preparation from FFPE sections |
| Transfer Solution | Thermo Fisher Scientific [11] | Facilitates tissue collection from slides | Sample transfer without degradation |
| Direct Reagent | Thermo Fisher Scientific [11] | Reverse crosslinks, neutralize inhibitors | Single-reagent processing of FFPE tissue |
| Phire Tissue Direct PCR Master Mix | Thermo Fisher Scientific [13] | Direct amplification from tissues | Bypassing extraction for PCR-based genotyping |
| ReliaPrep FFPE gDNA Miniprep System | Promega [12] | Traditional purification with mild deparaffinization | Alternative when direct methods are unsuitable |
Implementation Guidelines
Optimal Use Cases
The direct FFPE DNA protocol demonstrates particular strength in these research scenarios:
- Tumor Profiling Studies: Targeted sequencing panels for cancer biomarker discovery using limited archival material. [11]
- Historical Sample Analysis: Investigation of rare diseases or epidemiological trends where sample quantity is severely limited. [11]
- High-Throughput Screening: Processing large sample batches for population studies or clinical trial supporting data.
- Minimally Invasive Sampling: Applications where small biopsies or fine-needle aspirates provide minimal tissue quantity.
Technical Considerations
Successful implementation requires attention to several technical aspects:
Input Material Quality: While the protocol is robust, severely degraded samples may still present challenges in downstream applications.
Inhibition Management: The proprietary Direct Reagent effectively neutralizes common inhibitors, but extreme cases may require optimization.
Library Preparation Compatibility: The method is specifically optimized for AmpliSeq-based library preparation protocols and should be validated for other NGS approaches.
Quality Control: While optional quantification is possible, establishing laboratory-specific success criteria based on downstream performance is recommended.
The innovative approach of bypassing both deparaffinization and purification represents a paradigm shift in FFPE tissue processing that effectively addresses longstanding limitations in DNA quality, processing time, and sample conservation. By transforming a multi-step, technically challenging procedure into an efficient 30-minute workflow, this methodology significantly enhances the accessibility and utility of precious archival samples for modern genomic applications. The robust performance in targeted sequencing applications positions this technology as a fundamental advancement for researchers and drug development professionals leveraging retrospective sample collections for prospective discoveries.
Table of Contents
- Introduction
- Key Technical Specifications
- Research Reagent Solutions
- Experimental Workflow
- FFPE Sample Quality Control Protocol
- Library Preparation Protocol
- Data Analysis Workflow
The AmpliSeq for Illumina Direct FFPE DNA protocol provides a targeted sequencing solution for challenging formalin-fixed, paraffin-embedded (FFPE) tissue samples. This approach enables researchers to generate high-quality sequencing libraries without requiring DNA purification after amplification, streamlining the workflow for degraded FFPE samples commonly encountered in cancer research and drug development. The method leverages highly multiplexed PCR technology to amplify specific genomic regions of interest, making it particularly valuable for profiling cancer biomarkers and other clinical targets from limited and degraded sample materials [14].
This protocol is optimized for use with the AmpliSeq for Illumina Custom DNA Panels, which allow researchers to design targeted content specific to their research needs using the DesignStudio online tool. The flexibility to target between 12 to over 12,000 amplicons makes this system suitable for various applications, from focused variant detection to comprehensive genomic profiling [6].
Key Technical Specifications
Table 1: Comprehensive specifications for the AmpliSeq for Illumina Direct FFPE DNA workflow
| Specification Category | Detailed Parameters |
|---|---|
| Input Requirements | Quantity: 1–100 ng (10 ng recommended per pool) [6]Sample Type: FFPE tissue, Blood [6]Quality: No specific FFPE QC required [15] |
| Reaction Scale | Panel Size: 12 to 12,288 amplicons [6]Panel Reactions: 750 or 3000 reactions [6]Library PLUS Kit: 24, 96, or 384 reactions [6]Multiplexing Capacity: Up to 96 samples per run [6] |
| Compatible Instruments | Full Compatibility: MiSeq System, iSeq 100 System, NextSeq 550 System, NextSeq 2000 System, NextSeq 1000 System, MiSeqDx in Research Mode, MiniSeq System, NextSeq 550Dx in Research Mode [6]Extended Compatibility: NovaSeq X Series, NovaSeq 6000 Series [16] |
| Workflow Timing | Total Assay Time: ~5 hours (library prep only) [6]Hands-on Time: 1.5 hours [6] |
| Content Specifications | Custom Content: Up to 5 Mb genomic content [6]Species Compatibility: Human, Mouse, Bovine, Canine, Porcine, and many other species [6] |
| Methodology | Mechanism: Multiplex PCR [6]Applications: Custom sequencing, Targeted DNA sequencing, Amplicon sequencing, Genotyping by sequencing [6] |
Research Reagent Solutions
Table 2: Essential research reagents and materials for the Direct FFPE DNA protocol
| Component | Function | Specifications & Compatibility |
|---|---|---|
| AmpliSeq for Illumina Direct FFPE DNA Kit | Prepares DNA libraries directly from FFPE tissue without purification | Catalog #20023378; Includes 24 reactions [17] |
| AmpliSeq Library PLUS for Illumina | Library preparation master mix | Available in 24, 96, or 384 reactions [6] |
| AmpliSeq CD Indexes for Illumina | Sample multiplexing with unique barcodes | Multiple sets available (A-D); 8 bp indexes [6] |
| AmpliSeq for Illumina Custom DNA Panel | Target-specific primer pools | Custom content designed via DesignStudio; 12-12,288 amplicons [6] |
| Recommended Extraction Kits | Nucleic acid extraction from FFPE samples | QIAGEN AllPrep DNA/RNA FFPE Kit or Promega ReliaPrep FFPE gDNA MiniPrep System [15] |
| AmpliSeq for Illumina Sample ID Panel | Sample identification and tracking | Optional; includes SNP-targeting primer pairs [6] |
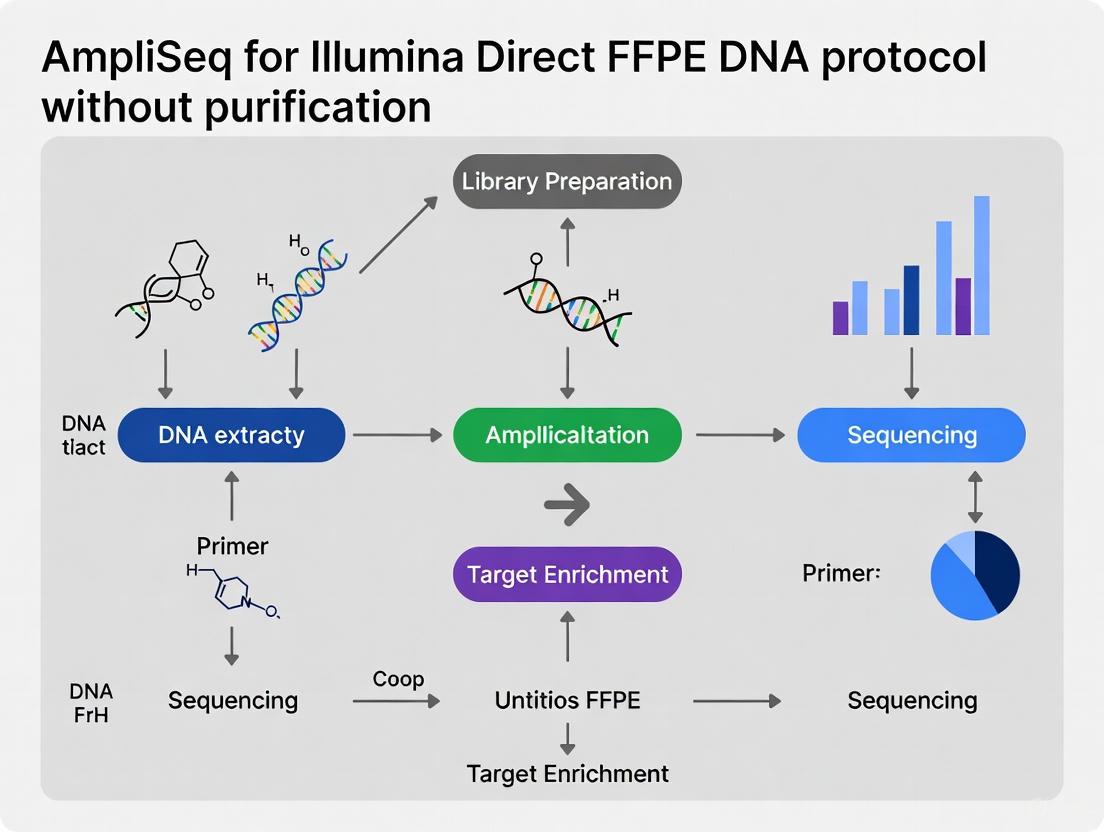
Experimental Workflow
Direct FFPE DNA Experimental Workflow: This diagram illustrates the streamlined process from FFPE tissue to sequencing data, highlighting the key steps where purification is eliminated.
FFPE Sample Quality Control Protocol
Sample Preparation Guidelines
For optimal results with the AmpliSeq Direct FFPE DNA protocol, proper sample preparation is essential:
- Tissue Section Requirements: Use at least 140 mm² of non-melanoma tissues with minimum 30% tumor content to ensure sufficient target material [15].
- DNA Extraction Methods: Employ validated FFPE extraction kits including:
- AllPrep DNA/RNA FFPE Kit (QIAGEN)
- QIAamp DSP DNA FFPE Tissue Kit (QIAGEN)
- ReliaPrep FFPE gDNA MiniPrep System (Promega) [15]
- Input DNA Quantification: Use fluorometric methods (e.g., Qubit) for accurate DNA quantification. Avoid UV-spectrometer-based methods which are less accurate for FFPE-derived DNA [15].
- Quality Control Consideration: Unlike other Illumina FFPE workflows, the AmpliSeq for Illumina panels require no specific FFPE QC, simplifying the preparatory steps [15].
Input DNA Optimization
While the protocol supports 1-100 ng input DNA, the recommended input is 10 ng per pool. Use 1 ng DNA only with high-quality, well-quantified samples. For degraded FFPE samples, maintain the 10 ng recommendation rather than reducing input, as the chemistry is optimized for challenging samples [6] [15].
Library Preparation Protocol
Multiplex PCR Amplification
The core amplification process utilizes highly multiplexed PCR:
- Reaction Setup: Combine 10 ng FFPE DNA with AmpliSeq Custom DNA Panel primers and Library PLUS master mix [6].
- Thermal Cycling: The optimized PCR conditions efficiently amplify targeted regions even from degraded FFPE DNA.
- Primer Digestion: Following amplification, enzymatic digestion cleaves remaining primers without requiring purification, significantly reducing hands-on time compared to traditional methods [6].
Library Construction and Indexing
- Partial Library Construction: The initial steps generate amplicon libraries ready for indexing.
- Index Adapter Ligation: Add unique dual indexes (UDIs) using AmpliSeq CD Indexes to enable sample multiplexing. The 8 bp indexes support up to 384-plex pooling strategies [6].
- Library Normalization: Use AmpliSeq Library Equalizer (catalog #20019171) for bead-based normalization, ensuring balanced representation across samples [17].
Library QC and Pooling
- Quality Assessment: Verify library quality using appropriate methods such as fragment analysis.
- Pooling Strategy: Pool up to 96 indexed libraries equimolarly based on quantification results.
- Sequencing Readiness: The final pooled libraries are ready for sequencing on compatible Illumina platforms without additional processing [6].
Data Analysis Workflow
Data Analysis Pathway: This workflow shows the streamlined analysis process from raw data to variant interpretation, specifically optimized for amplicon sequencing data.
Analysis Solutions
The AmpliSeq for Illumina ecosystem provides multiple analysis pathways:
- DRAGEN Amplicon Pipeline: Cloud-based secondary analysis that aligns reads against reference genomes and calls small variants with high accuracy [16].
- Local Run Manager: On-instrument analysis solution providing rapid results without extensive bioinformatics resources [16].
- Tertiary Analysis: Advanced analysis available through Correlation Engine for pathway analysis and biological interpretation [16].
Quality Metrics
Monitor these key performance indicators for optimal results:
- Coverage Uniformity: Assess evenness of coverage across all amplicons.
- On-Target Rate: Evaluate specificity of amplification.
- Variant Calling Accuracy: Verify detection sensitivity and specificity, particularly for low-frequency variants in FFPE samples.
The AmpliSeq for Illumina ecosystem provides a streamlined, multiplex PCR-based targeted sequencing solution, specifically engineered to generate highly accurate data from challenging sample types like Formalin-Fixed Paraffin-Embedded (FFPE) tissues without requiring DNA purification [18]. This integrated system enables researchers to rapidly prepare sequencing libraries for a comprehensive range of applications, including variant detection and gene expression analysis. The core of this ecosystem consists of three fundamental components: the AmpliSeq Library PLUS kit, Index Adapters, and specialized panels such as the AmpliSeq for Illumina Direct FFPE DNA Kit [18] [6]. This seamless integration is particularly valuable for cancer research and drug development, where working with degraded FFPE-derived DNA is common. The optimized workflow delivers exceptional performance with minimal input requirements (as low as 1 ng DNA) and significantly reduced hands-on time (under 1.5 hours), making it an ideal solution for laboratories processing valuable clinical research samples [18].
Key Components of the AmpliSeq Ecosystem
Research Reagent Solutions
The AmpliSeq ecosystem comprises several specialized kits and reagents designed to work together seamlessly. The table below details the essential components for establishing a complete FFPE research workflow.
Table 1: Core Components of the AmpliSeq for Illumina Ecosystem
| Component Name | Function | Key Specifications | Catalog Number Examples |
|---|---|---|---|
| AmpliSeq Library PLUS | Prepares amplicon libraries for Illumina sequencing; the core library prep kit. | ~5 hr assay time; <1.5 hr hands-on time; 1-100 ng input DNA [18]. | 20019101 (24 rxns), 20019102 (96 rxns), 20019103 (384 rxns) [18] |
| AmpliSeq CD Indexes | Allows sample multiplexing by attaching unique barcode sequences to each library. | Available in sets of 96 indexes (Set A-D); 8 bp index length [18] [6]. | 20019105 (Set A), 20019106 (Set B), 20019107 (Set C), 20019167 (Set D) [18] |
| AmpliSeq UD Indexes | Provides unique dual indexes for advanced multiplexing applications. | 24 indexes sufficient for 24 samples [18] [6]. | 20019104 [18] |
| AmpliSeq for Illumina Direct FFPE DNA Kit | Prepares DNA directly from slide-mounted FFPE tissues, bypassing deparaffinization and purification. | 24 reactions; enables library construction from unpurified FFPE samples [18] [6]. | 20023378 [18] |
| AmpliSeq Custom DNA Panel | Targets specific genomic regions of interest; designed via DesignStudio online tool. | 12 to 12,288 amplicons; content up to 5 Mb; for 750 or 3000 samples [6]. | 20020495 (<4999 amplicons), 20020497 (>4999 amplicons) [6] |
Workflow Integration and Specifications
The integrated AmpliSeq workflow supports a wide range of applications and sample types. The key specifications of the complete system are summarized in the table below.
Table 2: Comprehensive Specifications of the AmpliSeq for Illumina Workflow
| Parameter | Specification |
|---|---|
| Supported Instruments | MiSeq, iSeq 100, NextSeq 550/2000/1000, MiniSeq Systems [18] [6] |
| Supported Species | Human, Mouse, Rat, and virtually any species with predefined genomes available [18] |
| Variant Detection | SNPs, Indels, CNVs, Gene Fusions, Somatic and Germline Variants [18] |
| Specialized Sample Types | Blood, FFPE Tissue [18] [6] |
| Nucleic Acid Input | DNA or RNA [18] |
| Number of Amplicons | 12 to 12,288 per assay [18] [6] |
| Multiplexing Capacity | Up to 96-plex (using index adapters) [6] |
Experimental Protocol for Direct FFPE DNA Integration
Detailed Methodology
The following protocol outlines the integrated procedure for using the AmpliSeq for Illumina Direct FFPE DNA Kit with the Library PLUS and Index Adapters, creating a seamless workflow from FFPE tissue to a sequenced library.
Step 1: Sample Preparation via Direct FFPE DNA Kit
- Obtain unstained, slide-mounted FFPE tissue sections (5-10 µm thick). The Direct FFPE DNA Kit is designed to use these sections directly without the need for deparaffinization or DNA purification [18].
- Apply the provided reaction mix to the slide-mounted tissue. The specific enzymatic formulation digests the FFPE matrix and releases DNA while preserving its integrity for amplification [19].
- Incubate according to the kit's specified conditions to extract DNA. This step typically requires approximately 30 minutes, drastically reducing the sample preparation time compared to traditional methods [20].
Step 2: Target Amplification with Custom DNA Panel
- Use the extracted DNA directly in the target amplification reaction. The recommended input for the AmpliSeq workflow is 10 ng per pool, but the system is flexible and can accommodate a range from 1 to 100 ng, which is critical for degraded FFPE samples where DNA yield may be low [18] [6].
- Combine the DNA with the chosen AmpliSeq Custom DNA Panel and the AmpliSeq Library PLUS master mix. The custom panel, designed using the online DesignStudio tool, contains primer pools that multiplexly amplify the specific genes or regions of interest [6].
- Perform the PCR amplification using a verified thermal cycling profile. The proprietary primer formulations are optimized to handle the fragmented nature of FFPE-derived DNA, ensuring high specificity and uniform coverage across all targets [18].
Step 3: Partial Digestion and Adapter Ligation
- Following amplification, treat the amplicons with a proprietary enzyme blend provided in the Library PLUS kit to partially digest the primer sequences. This crucial step prepares the amplicon ends for the subsequent ligation of Illumina-specific adapters [18].
- Ligate the AmpliSeq CD Indexes or UD Indexes to the digested amplicons. This step barcodes each sample library, enabling sample multiplexing in downstream sequencing. For Set A-D CD Indexes, each set contains 96 unique 8-bp indexes [18].
- The ligation reaction is highly efficient, ensuring that the majority of amplicons are successfully tagged with both the P5/P7 flow cell binding sequences and the unique index sequence, which is essential for high-quality data output.
Step 4: Library Amplification and Normalization
- Amplify the ligated products using a final limited-cycle PCR. This enriches for properly constructed library fragments and adds the complete adapter sequences required for cluster generation on Illumina sequencers [18].
- Normalize the resulting libraries using the AmpliSeq Library Equalizer (Cat. No. 20019171) [18]. This bead-based normalization method ensures an equimolar representation of each library before pooling, which is critical for achieving balanced sequencing coverage across all samples in a multiplexed run.
- Quantify the normalized library pool using a sensitive method like qPCR to confirm the final concentration and quality before loading onto a sequencer.
Workflow Visualization
The following diagram illustrates the complete integrated workflow, from sample preparation to sequencing-ready libraries.
Diagram 1: Integrated AmpliSeq FFPE DNA workflow from sample to sequencing library.
Discussion and Application in Research
The integrated AmpliSeq ecosystem offers a powerful and streamlined solution for targeted sequencing of FFPE samples. The ability to bypass traditional DNA extraction and purification through the Direct FFPE DNA Kit not only saves time but also minimizes sample loss—a critical advantage when working with precious or limited clinical specimens [18] [6]. The synergy between the Library PLUS kit and the various index adapter sets provides researchers with a flexible and scalable system. This integration allows for efficient multiplexing of up to 96 samples in a single run using CD indexes, or advanced applications with unique dual indexes, maximizing throughput and reducing per-sample cost [18].
For the drug development and cancer research fields, this robust and reproducible workflow enables large-scale genomic profiling of archived FFPE samples. Researchers can reliably detect multiple variant types, including SNPs, indels, and CNVs, from low-input, degraded material, facilitating biomarker discovery and validation studies [18]. The availability of custom panels via DesignStudio further enhances the system's utility, allowing research teams to focus specifically on disease-relevant genes and pathways, thereby generating clinically actionable genomic information without the noise of whole-genome sequencing [6].
Targeted next-generation sequencing (NGS) has become a cornerstone of modern clinical and translational research, particularly in fields like oncology. The AmpliSeq for Illumina Direct FFPE DNA protocol addresses critical challenges in these fields by enabling robust sequencing from some of the most challenging but valuable sample types, such as formalin-fixed, paraffin-embedded (FFPE) tissues. These samples are a vast, retrospective resource for biomedical research, but their DNA is often degraded and cross-linked, making sequencing difficult. This application note details how the Direct FFPE DNA protocol provides significant time savings, workflow simplification, and sample preservation, thereby accelerating research and drug development.
Quantitative Benefits at a Glance
The following tables summarize the key quantitative advantages offered by the AmpliSeq for Illumina Direct FFPE DNA protocol, highlighting efficiency gains and workflow simplicity.
Table 1: Time Savings and Workflow Efficiency
| Parameter | Standard Workflow (with purification) | AmpliSeq Direct FFPE DNA Protocol | Benefit |
|---|---|---|---|
| Total Library Prep Time | ~6.5 hours or more [6] | ~5 hours [6] | Time savings of 1.5+ hours |
| Hands-on Time | Varies; typically several hours | ~1.5 hours [6] | Drastically reduced labor |
| Input DNA Quantity | Can require high inputs | 1–100 ng (10 ng recommended) [6] | Preserves precious samples |
| Multiplexing Capability | Varies by method | Up to 96-plex [6] | High throughput per run |
Table 2: Key Performance Metrics for Sample Preservation
| Metric | Description | Impact on Research |
|---|---|---|
| Compatibility with FFPE Tissues | Optimized for low-quality, degraded DNA from archived samples [6]. | Enables large-scale studies using retrospective clinical archives. |
| Low Input Requirement | Successful library preparation with as little as 1 ng of input DNA [7]. | Maximizes utility of limited or precious samples; minimizes "quantity not sufficient" (QNS) results. |
| Detection of Variant Types | Capable of detecting SNPs, indels, CNVs, and fusions from a single assay [21]. | Provides comprehensive genetic information from a minimal amount of sample. |
Experimental Protocol: AmpliSeq for Illumina Direct FFPE DNA Workflow
The following section provides a detailed methodology for utilizing the AmpliSeq for Illumina Direct FFPE DNA protocol in a research setting. The workflow is designed for simplicity and robustness.
The diagram below illustrates the streamlined, purification-free workflow for preparing sequencing libraries from FFPE DNA samples.
Detailed Step-by-Step Methodology
Sample Input and Quality Assessment
- Extract DNA from FFPE tissue sections using a standard method. The protocol is optimized for degraded DNA, so a high molecular weight is not required.
- Quantify DNA using a fluorometric method suitable for degraded FFPE-derived DNA. The input mass can range from 1 ng to 100 ng, with 10 ng being the recommended starting point [6].
Multiplex PCR Amplification
- In a single-tube reaction, combine the extracted DNA with the AmpliSeq for Illumina Custom DNA Panel primer pools and the AmpliSeq HiFi Mix [16] [6].
- The primer pools contain thousands of primer pairs designed to amplify the genomic regions of interest. The AmpliSeq technology uses an ultrahigh multiplex PCR approach, allowing for the simultaneous amplification of dozens to thousands of targets from a minimal amount of input material [7] [21].
- Perform PCR cycling as specified in the kit's reference guide [19].
Enzymatic Clean-up (Key Simplification Step)
Partial Adapter Addition
- The amplicons from the previous step are treated to partially attach Illumina sequencing adapter sequences. The streamlined nature of the protocol allows this to proceed without an intermediate purification.
Index PCR and Library Completion
- A second, short PCR is performed using Illumina index primers (e.g., AmpliSeq CD Indexes). This step simultaneously completes the adapter sequences and appends unique dual indices (UDIs) to each sample's amplicons [6].
- Indexing allows for the pooling of up to 96 libraries for a single sequencing run, enabling high-throughput studies [6].
Library Pooling and Sequencing
The Scientist's Toolkit: Essential Research Reagent Solutions
The successful implementation of the AmpliSeq for Illumina Direct FFPE DNA protocol relies on a suite of specialized reagents and tools. The table below lists the key components required for the workflow.
Table 3: Essential Reagents and Materials for the Direct FFPE DNA Workflow
| Item | Function | Example Product |
|---|---|---|
| Custom DNA Panel | Pools of primer pairs designed to amplify specific genomic regions of interest. | AmpliSeq for Illumina Custom DNA Panel (20020495) [6] |
| Library Preparation Kit | Provides essential enzymes and buffers for PCR, enzymatic clean-up, and adapter ligation. | AmpliSeq Library PLUS for Illumina (20019102) [6] |
| Index Adapters | Unique barcodes added to each sample's amplicons to allow multiplexing. | AmpliSeq CD Indexes Set A for Illumina (20019105) [6] |
| Sequencing System | Platform for performing next-generation sequencing. | iSeq 100, MiSeq, or NextSeq Series [16] [6] |
| Design Software | Free online tool for designing custom panels tailored to specific research goals. | DesignStudio Assay Design Tool [16] or Ion AmpliSeq Designer [22] |
Data Analysis Pathway
The output from the sequencing instrument is processed through a specialized bioinformatics pipeline to generate variant calls. The DRAGEN Amplicon pipeline on BaseSpace Sequence Hub or via Local Run Manager is optimized for this purpose, providing alignment and variant calling specifically for amplicon-based libraries [16].
The AmpliSeq for Illumina Direct FFPE DNA protocol represents a significant advancement in targeted sequencing for research. By eliminating purification steps, it delivers a faster, simpler workflow that reduces hands-on time from hours to approximately 90 minutes. Most importantly, its ability to generate high-quality sequencing data from as little as 1 ng of degraded FFPE DNA ensures that invaluable clinical samples are preserved for research. For scientists and drug development professionals, this translates to accelerated timelines, reduced operational complexity, and the ability to leverage vast archival sample repositories to uncover genetic drivers of disease.
Implementing the Direct FFPE DNA Protocol: A Step-by-Step Workflow and Panel Integration
Formalin-Fixed Paraffin-Embedded (FFPE) tissue specimens represent a cornerstone of biomedical research, particularly in oncology and molecular diagnostics. The integrity of these samples directly influences the success of downstream analytical techniques, including targeted next-generation sequencing (NGS) panels such as the AmpliSeq for Illumina Direct FFPE DNA protocol [23]. This methodology enables library construction without requiring DNA purification, placing paramount importance on the initial sample preparation stages [23]. Proper handling of slide-mounted sections is therefore not merely a preliminary step but a critical determinant of experimental success, especially within the context of advanced molecular protocols that bypass traditional purification. The following guidelines provide comprehensive, detailed procedures to ensure the recovery of high-quality genetic material from FFPE tissue sections, facilitating robust and reliable research outcomes.
Essential Research Reagent Solutions
The following reagents and kits are fundamental for the preparation and analysis of slide-mounted FFPE tissue sections.
Table 1: Key Research Reagents and Their Functions
| Reagent/Kits | Primary Function | Application Note |
|---|---|---|
| AmpliSeq for Illumina Direct FFPE DNA Kit [23] | Allows DNA preparation from FFPE tissues for direct library construction. | Designed for 24 reactions; eliminates need for deparaffinization or DNA purification, streamlining workflow. |
| Tissue Pretreatment Kit (e.g., LPS 100) [24] | Heat pretreatment and enzymatic digestion of FFPE tissue sections. | Optimizes tissue for subsequent probing; digestion time must be calibrated to fixation to preserve morphology [24]. |
| QIAamp DNA FFPE Tissue Kit (QIAGEN) [25] | Silica membrane-based DNA extraction. | Includes RNase treatment and a 90°C incubation step to reverse formalin cross-linkages [25]. |
| Cobas DNA Sample Preparation Kit (Roche) [25] | Glass fibre filter-based DNA isolation. | Yields high total DNA; includes a 90°C incubation step to reverse formalin cross-linkages [25]. |
| Maxwell 16 FFPE Plus LEV DNA Purification Kit (Promega) [25] | Automated purification using silica-clad paramagnetic particles. | Delivers DNA of the highest quality with a significantly higher concentration per µl [25]. |
| REPLI-g Kit (Qiagen) [26] | Multiple Displacement Amplification (MDA) for Whole-Genome Amplification (WGA). | Uses phi29 polymerase for high fidelity; can show skewed amplification patterns and overrepresentation [26]. |
| GenomePlex Kit (Sigma/Rubicon Genomics) [26] | Hybrid (isothermal & PCR-based) Whole-Genome Amplification (WGA). | Provides more uniform amplification with minimal variation in copy number and variant allele frequencies [26]. |
Detailed Experimental Protocol for Slide Preparation
This protocol provides a step-by-step methodology for preparing slide-mounted FFPE tissue sections for downstream DNA analysis, incorporating steps for fluorescence in situ hybridization (FISH) which shares critical preparatory steps with molecular techniques [24].
Sectioning and Initial Slide Handling
- Section Thickness: For procedures involving DNA retrieval or FISH, cut tissue sections to a thickness of 4μm to 6μm [24].
- Slide Adhesion: Treat microscopy slides with an adhesive (e.g., poly-L-lysine or silane) prior to tissue mounting to prevent detachment during subsequent rigorous processing steps [24].
- Dehydration and Deparaffinization: For protocols requiring it, deparaffinize slides using a series of washes: three washes in xylene for 3 minutes each, followed by three washes in 99.8% ethanol for 3 minutes each [25].
Macro-dissection of Tumor-Rich Regions
- Staining and Identification: Stain a parallel slide with Haematoxylin and Eosin (H&E). Have a qualified pathologist identify and mark the tumor-rich regions of interest on the H&E slide [25].
- Tissue Harvesting: Using the H&E slide as a guide, macrodissect the target regions from the unstained, serial FFPE tissue sections. This step enriches the tumor cell population and significantly decreases the risk of false-negative molecular results [25].
Heat Pretreatment and Enzymatic Digestion
This step is critical for breaking cross-links formed during formalin fixation and accessing the nucleic acids.
Figure 1: Workflow for FFPE Tissue Pretreatment and Digestion. This diagram outlines the key steps to prepare slide-mounted FFPE tissue sections for DNA analysis.
Heat Pretreatment:
- Immerse a Coplin jar containing 50ml of Tissue Pretreatment Solution (Reagent 1) in a water bath and heat to 98-100°C (boiling) [24].
- Immerse slides in the preheated solution and incubate for 30 minutes. Note: This duration is a starting point; optimal time may vary with fixation protocol [24].
- Wash slides in PBS or distilled water at room temperature (RT) for 2 washes of 3 minutes each [24].
Enzyme Digestion:
- Apply 100-200μl of Enzyme Reagent (Reagent 2) to completely cover the tissue section. Incubate for 10 minutes at RT [24].
- Critical Note: Excessive digestion will destroy tissue morphology and lead to loss of nuclei. Insufficient digestion will not adequately expose nucleic acids. Optimization based on tissue type and fixation is essential [24].
- Wash slides in PBS or distilled water at RT for 3 washes of 2 minutes each [24].
- Dehydrate slides through an ethanol series (70%, 85%, 95%, and 100% ethanol), incubating for 2 minutes in each concentration at RT. Air-dry the slides completely [24].
Quantitative Analysis of DNA Extraction Methods
The selection of a DNA extraction method significantly impacts the yield and quality of DNA recovered from FFPE tissues, which is critical for all downstream analyses.
Table 2: Comparison of DNA Yield and Purity from Three Commercial Kits [25]
| Extraction Method / Kit | Mean Quantity (ng/μl) - NanoDrop | Mean Quantity (ng/μl) - Qubit (dsDNA) | Mean Purity (A260/A280) | Elution Volume | Key Technology |
|---|---|---|---|---|---|
| Cobas (Roche) | 50.60 | 9.15 | 1.84 | 100 μl | Glass fibre filter |
| Maxwell (Promega) | 102.72 | 31.28 | 1.82 | 50 μl | Silica-clad paramagnetic particles |
| QIAamp (QIAGEN) | 18.00 | 4.79 | 1.78 | 100 μl | Silica membrane |
- Fluorometric vs. Spectrophotometric Quantification: Note the significant discrepancy in DNA concentration values obtained via spectrophotometry (NanoDrop) and fluorometry (Qubit). The Qubit system, being specific for double-stranded DNA (dsDNA), provides a more accurate assessment of usable DNA, as it is not influenced by contaminants or RNA [25].
- Total Yield Consideration: While the Maxwell kit yielded the highest DNA concentration per µl, the Cobas kit produced a comparable total yield due to its larger elution volume (100 µl vs. 50 µl) [25].
- Quality Assessment: The Maxwell and Cobas methods both produced DNA of significantly higher quality (purity closer to the ideal 1.8-2.0 ratio) compared to the QIAamp method [25].
Quality Assessment and Downstream Application
Ensuring the quality of the prepared sample is imperative before committing to resource-intensive downstream applications like NGS.
DNA Quality Control and Whole-Genome Amplification
For samples with limited DNA, Whole-Genome Amplification (WGA) can be employed, but the choice of method introduces specific biases.
Figure 2: Decision Pathway for DNA Analysis and WGA. This flowchart guides the choice of downstream steps based on DNA quality and research priorities.
- WGA Method Comparison:
- MDA (REPLI-g): Demonstrates high fidelity but can introduce significant bias, leading to overrepresentation of certain genomic regions and highly variable variant allele frequencies (VAF), making it less suitable for quantitative analyses [26].
- Hybrid Methods (GenomePlex): Show minimal variation in copy number and VAF, providing more uniform amplification and are therefore often better suited for clinical cancer samples targeted for NGS [26].
Integration with AmpliSeq for Illumina Direct FFPE DNA
The AmpliSeq for Illumina Direct FFPE DNA protocol is designed to bypass the need for DNA purification [23]. The sample preparation guidelines outlined in Section 3.0 are directly applicable to this workflow. The macro-dissected, pretreated tissue can be used directly in the kit's 24 reactions, leveraging the optimized chemistry to build sequencing libraries from minimally processed samples [23]. The quality of the initial tissue section and the efficacy of the pretreatment steps are, consequently, the primary variables influencing the success of the entire sequencing run.
The AmpliSeq for Illumina Direct FFPE DNA protocol represents a significant methodological advancement in genomic sequencing for cancer research and diagnostic applications. This innovative approach enables researchers to generate sequencing-ready libraries directly from formalin-fixed, paraffin-embedded (FFPE) tissue sections without requiring traditional DNA purification steps [11]. The protocol addresses a critical challenge in biomedical research: leveraging the vast archives of FFPE tissue samples stored in clinical biobanks worldwide, which constitute an invaluable resource for retrospective studies and biomarker discovery [27].
FFPE tissues represent the most accessible biological resource in both research and clinical settings due to their widespread use for preserving tissue morphology. However, conventional methods for processing these samples involve complex, multi-step procedures including deparaffinization and DNA extraction, which require considerable hands-on time and often result in significant sample loss [11]. The AmpliSeq Direct FFPE DNA protocol eliminates these bottlenecks through a streamlined workflow that minimizes sample handling and preserves precious molecular material that would otherwise be lost during purification. This is particularly crucial for FFPE samples, which often contain limited amounts of fragmented nucleic acids [28] [8].
The global FFPE tissue samples market for genomics study and analysis, valued at approximately USD 937 million in 2024, underscores the significance of these samples in contemporary biomedical research [27]. Within this market, DNA-based genomic analysis constitutes the major share (62%), reflecting the continued importance of DNA-level investigations in cancer genomics and other fields [27]. The AmpliSeq Direct FFPE DNA protocol directly addresses the needs of this expanding market by enabling reliable genomic analysis from challenging sample types that were previously considered suboptimal for next-generation sequencing.
Technical Workflow: From FFPE Section to Sequencing Library
Core Principles and Innovations
The AmpliSeq for Illumina Direct FFPE DNA protocol is founded on two key technical innovations that distinguish it from conventional approaches. First, it completely eliminates the need for deparaffinization and DNA purification, thereby minimizing sample loss and preserving the often-limited DNA present in FFPE tissues [11]. Second, it incorporates an optional uracil-D-glycosylase treatment step to address cytosine deamination, a common artifact in FFPE-derived DNA that can lead to erroneous base calls in sequencing data [11].
This direct approach is particularly advantageous for processing FFPE samples with limited DNA content, as it avoids the substantial sample loss associated with column- or bead-based purification methods. The protocol is designed to work with FFPE tissue sections up to 10 μm thick, making it compatible with standard histopathology specimens [11]. The streamlined nature of this workflow reduces hands-on time to approximately 10 minutes for the initial sample processing steps, enabling rapid preparation of multiple samples in parallel [11].
Step-by-Step Protocol Walkthrough
The following diagram illustrates the streamlined, purification-free workflow of the AmpliSeq for Illumina Direct FFPE DNA protocol:
Sample Collection and Transfer
The protocol begins with the collection of FFPE tissue sections mounted on standard glass slides. Using a sterile scalpel or blade, the region of interest is carefully excised from the section. The tissue fragment is then transferred to a PCR tube or 96-well plate using the provided Transfer Solution [11]. This step is particularly advantageous for samples where precise macrodissection is required to isolate specific tissue regions, such as tumor-rich areas while excluding normal tissue or stromal components [8]. Pathologist-assisted macrodissection ensures that the analysis focuses on the biologically relevant tissue compartment, significantly enhancing the quality and interpretability of resulting sequencing data.
Direct Lysis and DNA Liberation
After tissue transfer, Direct Reagent is added to the sample, followed by incubation at 65°C for 15 minutes [11]. This single-step reaction simultaneously accomplishes deparaffinization, lysis, and DNA liberation without requiring further purification. The Direct Reagent is formulated to break down paraffin, dissolve cross-links introduced during formalin fixation, and release DNA fragments in a form compatible with subsequent enzymatic steps in the AmpliSeq library preparation workflow. The entire process from FFPE section to DNA ready for library construction takes approximately 30 minutes with only 10 minutes of hands-on time [11].
Library Preparation and Amplification
The liberated DNA proceeds directly to the standard AmpliSeq for Illumina library preparation protocol. This involves targeted amplification using panels specifically designed for FFPE-derived DNA, such as the AmpliSeq for Illumina Cancer HotSpot Panel v2 (investigating 50 genes with known cancer associations) or the AmpliSeq for Illumina Comprehensive Cancer Panel (covering exonic regions of 409 cancer-associated genes) [28]. The protocol requires only 1 ng of input DNA, making it suitable for samples with limited nucleic acid content [11]. Following amplification, libraries are normalized and prepared for sequencing on Illumina platforms.
Essential Research Reagents and Materials
Successful implementation of the AmpliSeq for Illumina Direct FFPE DNA protocol requires specific reagents and materials designed to support the purification-free workflow. The table below details the essential components of the research toolkit:
Table 1: Key Research Reagent Solutions for the Direct FFPE DNA Protocol
| Reagent/Material | Function | Specifications |
|---|---|---|
| Transfer Solution | Facilitates transfer of tissue from glass slide to reaction vessel without loss of material | 240 μL provided in kit; enables precise collection of dissected tissue regions [11] |
| Direct Reagent | Single-reagent formulation for deparaffinization, lysis, and DNA liberation | 170 μL provided in kit; eliminates need for separate purification steps [11] |
| AmpliSeq Primer Panels | Target-specific primers for focused genomic regions | Available as fixed panels (e.g., Cancer HotSpot Panel v2) or custom designs [28] |
| Ion AmpliSeq Direct FFPE DNA Kit | Complete reagent set for direct FFPE processing | Available in 8-preparation or 96-preparation formats [11] |
| Uracil-D-glycosylase (Optional) | Enzyme treatment to remove deaminated cytosines | Redces sequencing artifacts common in FFPE-derived DNA [11] |
Additional recommended materials include the Qubit HS DNA Quantitation Kit for measuring DNA concentration if quantification is necessary, though the direct protocol is designed to proceed without mandatory quantification [11]. For automated processing, the protocol is compatible with the Ion Chef System, enabling walkaway automation of library preparation [11].
Performance Metrics and Technical Considerations
Protocol Advantages and Limitations
The AmpliSeq Direct FFPE DNA protocol offers several significant advantages over conventional approaches. The most notable benefit is the substantial reduction in sample loss, as the elimination of purification steps preserves precious DNA that would otherwise be lost [11]. This is particularly critical for small biopsies or samples with limited tumor content. Additionally, the protocol offers remarkable workflow efficiency, reducing hands-on time to just 10 minutes for the initial processing steps and completing the entire sample preparation in approximately 30 minutes [11].
However, researchers should consider certain limitations. The protocol is optimized for targeted sequencing approaches rather than whole-genome sequencing, as the fragmented nature of FFPE-derived DNA presents challenges for comprehensive genomic coverage [28]. Additionally, while the optional uracil-D-glycosylase treatment helps mitigate deamination artifacts, some base modifications characteristic of FFPE tissue may still affect sequencing accuracy [11].
Comparison with Alternative Methodologies
When compared to other FFPE-compatible workflows, the AmpliSeq Direct approach demonstrates distinct advantages in processing efficiency and sample conservation. The table below summarizes key performance metrics:
Table 2: Performance Comparison of FFPE-Compatible DNA Sequencing Methods
| Method | Input Requirements | Hands-On Time | Total Processing Time | Key Applications |
|---|---|---|---|---|
| AmpliSeq Direct FFPE DNA Protocol | 1 ng DNA; FFPE sections up to 10 μm | 10 minutes | 30 minutes (direct processing) | Targeted sequencing, cancer hotspot panels [11] |
| Illumina DNA Prep | 100-500 ng DNA for large genomes | 1-1.5 hours | 3-4 hours | Whole-genome sequencing, amplicon sequencing [29] |
| Conventional FFPE DNA Extraction | Varies; significant sample loss | 30-60 minutes | 3-6 hours (including extraction) | Multiple applications requiring purified DNA [11] |
| Methylation Capture Sequencing | 5 million CpG sites at 10× depth | Not specified | Not specified | Methylation profiling, epigenomics [30] |
The data demonstrates that the AmpliSeq Direct protocol offers the most efficient workflow for targeted sequencing applications from FFPE samples, particularly when processing time and sample conservation are primary considerations.
Implementation Guidelines and Future Directions
Quality Control Considerations
Successful implementation of the AmpliSeq Direct FFPE DNA protocol requires careful attention to quality control measures. Prior to library preparation, researchers should evaluate RNA integrity (when applicable) using metrics such as DV200 values (percentage of RNA fragments >200 nucleotides), with values below 30% indicating excessively degraded samples [8]. For DNA, functional quality assessment through PCR-based methods is recommended, as traditional spectrophotometric measurements may not accurately reflect the amplifiable DNA content in direct processing protocols.
The protocol is designed to work with FFPE samples exhibiting a range of degradation levels, but samples with extreme degradation (e.g., very low DV200 values for RNA or completely unamplifiable DNA) may still present challenges [8]. Illumina provides specific FFPE quality control recommendations to help researchers determine whether their FFPE samples constitute viable input material for library preparation [28].
Integration with Emerging Technologies
The AmpliSeq Direct FFPE DNA protocol is positioned to integrate with several emerging genomic technologies. Of particular relevance is the Illumina 5-base solution for methylation studies, which enables simultaneous detection of genetic variants and methylation patterns in a single assay [31]. Future developments aim to expand compatibility of this technology with FFPE tissues, creating opportunities for combined genetic and epigenetic analysis from direct FFPE processing [31].
Additionally, the growth of artificial intelligence applications in genomic analysis presents new opportunities for extracting enhanced insights from FFPE-derived sequencing data. AI algorithms are increasingly capable of addressing FFPE-specific challenges such as DNA degradation artifacts and can process large datasets generated through targeted sequencing [27]. The expansion of spatial transcriptomics technologies, including Illumina's spatial technology scheduled for release in the first half of 2026, will complement the DNA-focused AmpliSeq approach by enabling precise spatial mapping of gene expression patterns in FFPE tissues [31].
Concluding Recommendations
The AmpliSeq for Illumina Direct FFPE DNA protocol represents a significant advancement in making genomic analysis of archival tissues more accessible, efficient, and reliable. Researchers implementing this protocol should:
- Prioritize sample selection through careful pathological review and, when necessary, macrodissection to ensure target tissue enrichment
- Implement appropriate quality control measures both before and during library preparation to identify potential issues early
- Consider the optional uracil-D-glycosylase treatment for samples with suspected high levels of cytosine deamination
- Leverage the protocol's compatibility with automation for studies involving large sample numbers
- Stay informed about emerging technologies that may enhance or complement the direct FFPE approach
As precision medicine continues to evolve, methodologies that maximize the utility of precious clinical samples like FFPE tissues will play an increasingly important role in translating genomic discoveries into improved patient care.
AmpliSeq technology utilizes a highly multiplexed polymerase chain reaction (PCR) approach for targeted next-generation sequencing (NGS), enabling efficient amplification of specific genomic regions from minimal DNA or RNA input. This methodology is particularly transformative for research involving formalin-fixed, paraffin-embedded (FFPE) tissues, where DNA is often degraded and limited in quantity. The AmpliSeq for Illumina Direct FFPE DNA protocol revolutionizes this workflow by eliminating the need for traditional DNA purification and deparaffinization steps [32]. This direct approach significantly reduces hands-on time and minimizes sample loss, making it possible to generate sequencing libraries from as little as 1 ng of input DNA with just 10 minutes of active hands-on time in a simplified 30-minute protocol [20] [32]. For researchers investigating T-cell biology, cancer genomics, and other specialized applications, this streamlined workflow combines with various AmpliSeq panel formats—including ready-to-use, custom, on-demand, and specialized TCR beta-SR panels—to provide comprehensive solutions for targeted sequencing needs across diverse research contexts.
Table: Key Characteristics of AmpliSeq Direct FFPE DNA Workflow
| Parameter | Specification | Research Benefit |
|---|---|---|
| Input Material | FFPE tissue sections (up to 10 µm thick) | Utilizes archived clinical samples |
| Hands-on Time | ~10 minutes | Enables high-throughput processing |
| Total Protocol Time | ~30 minutes | Rapid turnaround from sample to result |
| DNA Input Requirement | 1-100 ng | Compatible with limited/degraded samples |
| Key Omitted Steps | Deparaffinization, column/bead-based purification | Minimizes sample loss and processing artifacts |
Available AmpliSeq Panel Types and Applications
AmpliSeq panels are available in multiple configurations designed to address different research requirements and content needs. These panels leverage the same fundamental multiplex PCR technology but vary in their target content, design process, and implementation flexibility.
Ready-to-Use and Community Panels
Ready-to-use panels provide predesigned content targeting genes associated with specific diseases or phenotypes, offering researchers the fastest path to NGS results without the need for custom design work. These panels are ideal for common research applications in cancer research, inherited disease studies, and immunology, where the gene targets are well-established and standardized content is sufficient [16] [33]. The AmpliSeq for Illumina TCR beta-SR Panel represents a specialized ready-to-use solution designed specifically for measuring T-cell diversity and clonal expansion in tumor samples by sequencing T-cell receptor beta chain rearrangements, making it particularly valuable for cancer immunology studies and immunotherapy response monitoring [16]. Community panels represent a specialized category of predesigned content developed with input from leading disease researchers, offering verified performance for specific research domains such as the Ion AmpliSeq Liverpool Lymphoid Network Panel, which is now available in smaller pack sizes to accommodate projects with lower throughput requirements [34].
Custom and On-Demand Panels
When predesigned panels do not match research needs, AmpliSeq offers multiple custom solutions. Ion AmpliSeq On-Demand Panels provide practical customization through smaller pack sizes of pre-tested genes, reducing upfront costs and enabling researchers to iterate panel designs for human disease research with greater efficiency and convenience [7]. These panels are particularly valuable for research on inherited diseases, cancer biomarkers, and pharmacogenomics, where established gene sets require minor modifications for specific study designs. For maximum flexibility, fully custom Made-to-Order panels allow researchers to design completely novel content using the free online Ion AmpliSeq Designer tool, which supports both standard human reference genomes (hg19, hg38) and user-provided reference sequences for non-human species [22] [7]. The custom design process now includes an application area specification with options for cancer research (multiple sample types), reproductive health research, genetic disorders research, microbial/infectious disease research, pharmacogenomics research, human identification research, and agricultural/breeding research [34].
Specialized TCR Beta Sequencing Panels
T-cell receptor beta (TCRβ) sequencing panels represent a specialized application of AmpliSeq technology for immunology, immuno-oncology, and vaccine research. The Ion AmpliSeq Mouse TCR Beta SR Assay is a robust, targeted NGS assay designed to identify and measure the clonal expansion of T lymphocytes by targeting the complementarity-determining region 3 (CDR3) of the T-cell receptor beta chain gene locus from gDNA input [35]. This technology enables researchers to track specific T-cell clones since the nucleotide sequence of the CDR3 region is unique to each T cell and codes for the part of the TCR beta chain involved in antigen recognition [35]. The assay demonstrates high sensitivity and specificity with flexible input requirements (100 ng–1 μg), dual-barcode indexing for rare clone identification, and compatibility with various research sample types including fresh-frozen and FFPE tissue, whole blood, peripheral blood leukocytes, and peripheral blood mononuclear cells [35].
Diagram 1: AmpliSeq Direct FFPE DNA workflow showing the simplified sample processing pathway and compatible panel options for downstream analysis.
Research Reagent Solutions and Experimental Specifications
Successful implementation of AmpliSeq panels with direct FFPE DNA protocols requires specific reagent systems and careful consideration of experimental parameters. The key components include specialized kits for sample processing, library preparation, and appropriate panel selection based on research objectives.
Table: Essential Research Reagents for AmpliSeq Direct FFPE DNA Workflows
| Component | Function | Specifications | Compatibility |
|---|---|---|---|
| Direct FFPE DNA Kit | Extraction of DNA from FFPE samples without purification | 30-minute protocol, 10 min hands-on, no deparaffinization | All AmpliSeq panels [32] |
| AmpliSeq Library Kit Plus | Library preparation from amplified targets | Includes primer digestion, barcode adapter ligation | Ion AmpliSeq panels [35] |
| TCR Beta-SR Assay | Target enrichment for T-cell receptor sequencing | 90-bp amplicons, CDR3 region focus | Mouse models, immunotherapy studies [35] |
| dNTP Mix | PCR amplification nucleotides | 25 mM concentration, included in kits | All AmpliSeq library prep workflows [35] |
| Qubit dsDNA HS Assay | DNA quantification post-extraction | High-sensitivity detection | Quality control step [20] |
The Ion AmpliSeq Direct FFPE DNA Kit (Catalog number: A31136) enables preparation of DNA from formalin-fixed, paraffin-embedded tissues for library construction without the need for deparaffinization or DNA purification, using a simple one-tube, two-step protocol that minimizes sample loss [32]. This kit is suitable for FFPE tissue sections up to 10 µm thick and includes an optional uracil-diglycosylase treatment to remove deaminated cytosines—a common issue in FFPE-derived DNA that can cause artifactual mutations [32]. For TCR beta sequencing applications, the Ion AmpliSeq Mouse TCR Beta SR Assay (Catalog number: A45488) provides a complete solution with a single pool of multiplex PCR primers and library reagents to generate 90-bp amplicons targeting the CDR3 region, compatible with all chip types supported by Ion GeneStudio S5 sequencing systems [35].
Technical Methodologies and Implementation Protocols
Direct FFPE DNA Processing Methodology
The Direct FFPE DNA protocol represents a significant departure from traditional nucleic acid extraction methods. The experimental workflow begins with FFPE tissue sections mounted on glass slides, from which the area of interest is removed using Transfer Solution and transferred directly into a PCR tube or 96-well plate [32]. After adding Direct Reagent, samples are incubated at 65°C for 15 minutes, after which the DNA is ready for immediate use in AmpliSeq library preparation without further purification [32]. This approach preserves the limited DNA quantity typically obtained from archived specimens while eliminating the sample loss associated with column- or bead-based purification methods. For quality assessment, the extracted DNA can be quantified using the Qubit HS DNA Quantitation Kit, though this optional step may be omitted when sample material is extremely limited [32]. The entire process demonstrates remarkable efficiency, enabling researchers to process samples from FFPE tissue sections to sequencing-ready DNA in approximately 30 minutes with only 10 minutes of hands-on time, making it particularly suitable for high-throughput research environments [32].
Library Preparation and Sequencing Parameters
Following direct DNA preparation, the AmpliSeq library construction process utilizes highly multiplexed PCR to amplify targeted regions of interest. The experimental protocol requires 1-100 ng of input DNA, with optimal performance demonstrated across this entire range for most applications [20]. For the Ion AmpliSeq Mouse TCR Beta SR Assay, the recommended input range is slightly higher at 100 ng–1 μg, reflecting the need for comprehensive coverage of diverse T-cell receptor sequences [35]. Library preparation begins with multiplexed PCR amplification using panel-specific primers, followed by enzymatic digestion of remaining primers and ligation of barcode adapters for sample multiplexing [16]. The complete workflow from library preparation to data analysis can be accomplished in two days using automated systems such as the Ion Chef templating system and Ion GeneStudio S5 sequencing system, with the TCR Beta SR Assay specifically generating 90-bp amplicons optimized for detecting CDR3 region diversity [35]. For Illumina sequencing platforms, the AmpliSeq for Illumina workflow requires approximately 5-7 hours for library preparation (with 1.5 hours hands-on time) followed by 17-32 hours of sequencing time, depending on the specific Illumina instrument and sequencing parameters selected [16].
Diagram 2: Step-by-step methodology for AmpliSeq library preparation from FFPE samples, highlighting key procedural stages and compatible panel selection points.
Data Analysis and Bioinformatics Pipeworks
Data analysis for AmpliSeq panels utilizes specialized bioinformatics pipelines tailored to the specific research application. For TCR beta sequencing experiments, the analysis focuses on identifying CDR3 region sequences and quantifying their relative abundance to measure clonal expansion and T-cell diversity [35]. For cancer panels, analysis typically includes small variant calling (SNPs, indels), copy number variation assessment, and in some cases gene fusion detection [7]. The Ion Reporter Software (v5.12 and later) provides a comprehensive solution for analyzing data from Ion Torrent sequencing systems, with specific workflows available for different panel types [35]. For Illumina platforms, researchers can utilize the DRAGEN Amplicon pipeline for cloud-based analysis or Local Run Manager for on-instrument processing, both of which provide alignment against reference genomes and variant calling capabilities without requiring extensive bioinformatics resources [16]. These analysis solutions enable researchers to progress rapidly from raw sequencing data to biologically interpretable results, with the entire workflow—from DNA extraction to analyzed data—achievable in as little as 24-48 hours depending on the sequencing platform and panel complexity [35] [16].
Application-Specific Panel Selection Guidelines
Choosing the appropriate AmpliSeq panel requires careful consideration of research objectives, sample types, and throughput requirements. The following guidelines facilitate optimal panel selection for different experimental scenarios.
Immuno-Oncology and T-Cell Research
For investigations of T-cell repertoire dynamics, immunotherapy response mechanisms, and tumor microenvironment immunology, the specialized TCR beta-SR panels provide targeted solutions. The Ion AmpliSeq Mouse TCR Beta SR Assay enables basic and translational research to identify T-cell clones by sequencing the CDR3 region of the T-cell receptor beta chain, which is unique to each T cell and fundamental to antigen recognition [35]. This assay demonstrates particular utility for studying checkpoint blockade inhibitors, cancer vaccines, and chimeric antigen receptor (CAR) T-cell therapies in mouse models, with high sensitivity enabled through dual-barcode indexing for rare clone identification [35]. The technology supports various research sample types including fresh-frozen and FFPE tissue, whole blood, peripheral blood leukocytes, and peripheral blood mononuclear cells, making it applicable to diverse experimental designs [35]. When implementing this assay with direct FFPE DNA protocols, researchers should note the slightly higher DNA input requirements (100 ng–1 μg compared to 1-100 ng for standard panels) to ensure comprehensive coverage of T-cell receptor diversity.
Custom Panel Design Strategies
When predesigned panels do not address specific research needs, the Ion AmpliSeq Designer tool provides a free online platform for creating customized targeted sequencing panels [22]. The design process begins with selecting the appropriate custom panel type based on content needs and throughput requirements: On-Demand Panels for smaller pack sizes of pre-tested genes, Made-to-Order Panels for complete customization, or AmpliSeq HD Panels for ultra-high sensitivity applications requiring detection of low-frequency variants down to 0.1% [7] [34]. Researchers must specify the application area during design creation, with options including various cancer research categories (solid tumor, liquid biopsy, heme, inherited cancers), reproductive health research, genetic disorders research, microbial/infectious disease research, pharmacogenomics research, human identification research, and agricultural/breeding research [34]. Recent enhancements to the design tool include pool preservation functionality that maintains original pool assignments when copying amplicons between designs, and updated support for COSMIC v97 and dbSNP v156 databases for both hg19 and hg38 human reference genomes [34]. For non-human species, custom panels can be designed from 13 predefined genomes or user-provided reference sequences [7].
Table: Performance Specifications for AmpliSeq Panel Categories
| Panel Type | Optimal DNA Input | Key Applications | Sensitivity | Time to Results |
|---|---|---|---|---|
| Direct FFPE DNA | 1-100 ng [20] | All FFPE-based sequencing | >95% uniformity, >97% on-target [20] | ~30 min processing [32] |
| TCR Beta-SR | 100 ng–1 μg [35] | T-cell clonality, Immuno-oncology | Rare clone detection [35] | 48 hours total [35] |
| On-Demand Custom | 1-100 ng [20] | Inherited disease, Cancer genomics | Standard variant calling | 24-48 hours [16] |
| AmpliSeq HD | 1-100 ng [7] | Liquid biopsy, Microbial detection | 0.1% LOD [7] | 24-48 hours [16] |
AmpliSeq technology provides a versatile and efficient targeted sequencing solution that integrates seamlessly with direct FFPE DNA processing methodologies. The availability of specialized TCR beta-SR panels, customizable on-demand content, and predesigned community panels offers researchers multiple pathways to address diverse scientific questions while leveraging the significant advantages of the direct FFPE workflow—minimal sample input, reduced processing time, and elimination of purification-related DNA loss. The recent advancements in panel design capabilities, including application-specific configurations and enhanced bioinformatics support, further strengthen the utility of this technology for modern research applications spanning immuno-oncology, inherited disease, infectious disease, and pharmacogenomics. By selecting appropriate panel types and following optimized experimental protocols, researchers can efficiently generate high-quality sequencing data from challenging FFPE samples, accelerating discovery across multiple scientific domains.
Formalin-fixed, paraffin-embedded (FFPE) tissues present unique challenges for genomic analysis due to DNA fragmentation and cross-linking [28]. The AmpliSeq for Illumina targeted sequencing solution is specifically designed to overcome these challenges, enabling robust sequencing of low-input and degraded DNA samples [16]. This technology utilizes a multiplexed PCR-based workflow to amplify genomic regions of interest with as little as 1 ng of DNA input, making it particularly suitable for FFPE-derived genetic material [16]. A critical factor in research success is selecting the appropriate sequencing platform that aligns with the specific requirements of the project.
The MiSeq, NextSeq, and iSeq systems from Illumina offer complementary capabilities for targeted sequencing applications [36]. These platforms leverage proven Sequencing by Synthesis (SBS) chemistry but differ significantly in their throughput, run times, and data output characteristics [37] [38] [39]. For AmpliSeq for Illumina Direct FFPE DNA protocol without purification research, understanding these platform specifications is essential for designing efficient experiments that deliver high-quality, reliable data. The compatibility of AmpliSeq panels across all Illumina sequencing systems provides researchers with flexibility in platform selection based on their specific project scope and requirements [16].
Technical Specifications and Platform Comparison
Comprehensive Platform Specifications
Table 1: Comprehensive technical specifications for Illumina benchtop sequencing platforms relevant for AmpliSeq for Illumina applications. [36] [37] [38]
| Platform | Maximum Output | Read Length | Reads per Run | Run Time | Quality Scores (Q30) |
|---|---|---|---|---|---|
| iSeq 100 | 1.2 Gb | 2 × 150 bp | 4M single-end / 8M paired-end | 9.5–19 hours | >80% (2 × 150 bp) |
| MiSeq | 15 Gb | 2 × 300 bp | 25M single-end / 50M paired-end | 5–55 hours | >70% (2 × 300 bp) |
| MiSeq i100 Series | 30 Gb | 2 × 500 bp | 100M single-end / 200M paired-end | ~4–24 hours | ≥85% (2 × 300 bp) |
| NextSeq 550 | 120 Gb | 2 × 150 bp | 400M single-end / 800M paired-end | 11–29 hours | >75% (2 × 150 bp) |
| NextSeq 1000/2000 | 540 Gb | 2 × 150 bp | 1.8B single-end / 3.6B paired-end | 8–44 hours | ≥90% (2 × 150 bp) |
Platform Selection Guidance
When selecting a sequencing platform for AmpliSeq for Illumina Direct FFPE DNA protocol research, researchers should consider several key parameters. The iSeq 100 System offers the most compact footprint and rapid turnaround times (9.5-19 hours), making it ideal for small-scale targeted sequencing studies or quality control applications [39] [40]. However, it's important to note that Illumina has announced the obsolescence of the iSeq 100 System, with ordering available until September 30, 2025, and reagent support through December 31, 2029 [40]. The MiSeq i100 Series is recommended as its alternative, offering significantly higher output (up to 30 Gb) and faster run times (as little as ~4 hours) with room temperature-stable reagents that expedite sequencing setup [41].
For medium to high-throughput projects, the NextSeq 550 System provides a balanced solution with output up to 120 Gb, capable of processing multiple exomes or transcriptomes in a single run [42]. The NextSeq 1000/2000 Systems represent the highest throughput benchtop options, delivering exceptional data quality (≥90% bases above Q30) through innovative XLEAP-SBS chemistry and patterned flow cell technology [38]. These systems are particularly valuable for large-scale FFPE studies requiring consistent, high-quality data across hundreds of samples.
Experimental Protocols for AmpliSeq for Illumina Direct FFPE DNA Protocol
Library Preparation Workflow
The AmpliSeq for Illumina workflow for FFPE samples begins with DNA extraction from formalin-fixed, paraffin-embedded tissue specimens. FFPE extraction methods generally yield highly degraded DNA and RNA, requiring specialized quality control assessment to determine sample viability [28]. The library preparation process requires approximately 5-7 hours total hands-on time, with only about 1.5 hours of active involvement [16].
The protocol initiates with multiplexed PCR amplification of targeted genomic regions using as little as 1 ng of input DNA [16]. This is followed by enzymatic digestion of remaining primers to prevent interference with downstream steps. The purified amplicons are then prepared for sequencing using a streamlined process that minimizes sample manipulation, reducing the risk of sample loss or contamination—a critical consideration when working with precious FFPE specimens. The entire process from DNA to sequencing-ready libraries can be completed within a single day, enabling rapid turnaround for research projects.
Platform-Specific Sequencing Protocols
Table 2: Recommended sequencing parameters for AmpliSeq for Illumina panels across different platforms. [37] [38] [39]
| Platform | Recommended Read Length | PhiX Spike-In | Optimal Cluster Density | Library Concentration |
|---|---|---|---|---|
| iSeq 100 | 2 × 150 bp | 10% | 174–200 k/mm² | 55 pM |
| MiSeq | 2 × 300 bp | 30% | 1200–1400 k/mm² | 10 pM |
| MiSeq i100 Series | 2 × 300 bp | Varies by application | System-defined | Varies by flow cell |
| NextSeq 550 | 2 × 150 bp | 1–5% | 129–165 k/mm² | 1.2–1.8 pM |
| NextSeq 1000/2000 | 2 × 150 bp | 1–5% | Manufacturer-optimized | Manufacturer-optimized |
For the iSeq 100 System, library denaturation is not required, and the final library concentration should be adjusted to 55 pM [43]. In contrast, MiSeq protocols require library denaturation with NaOH and a final concentration of 10 pM [43]. The NextSeq systems utilize more complex flow cells and require lower library concentrations (1.2-1.8 pM) with minimal PhiX spike-in (typically 1-5%) to ensure optimal cluster distribution and data quality [38] [42].
A comparative study evaluating 16S rRNA sequencing on iSeq and MiSeq platforms revealed notable differences in data quality and depth [43]. While the iSeq platform enabled three-fold faster sequencing time compared to MiSeq, it demonstrated lower species richness and alpha diversity measurements, particularly at finer taxonomic levels [43]. This suggests that platform selection should be guided by the required resolution, with MiSeq being more appropriate for studies requiring detection of rare variants or detailed compositional differences.
Workflow Visualization
The workflow begins with FFPE tissue sectioning and proceeds through DNA extraction, which typically yields fragmented nucleic acids requiring quality assessment [28]. The AmpliSeq library preparation follows, utilizing a multiplexed PCR approach to amplify targeted regions from minimal DNA input (as little as 1 ng) [16]. Platform selection is determined by project scale: iSeq 100 for small-scale studies or quality control, MiSeq Series for medium-throughput projects requiring longer read lengths, and NextSeq Series for large-scale studies demanding high throughput [36] [40]. Data analysis can be performed using on-instrument DRAGEN pipelines or cloud-based solutions through BaseSpace Sequence Hub [16] [40].
Research Reagent Solutions
Table 3: Essential research reagents and their applications for AmpliSeq-based FFPE DNA studies. [16] [28]
| Reagent Solution | Function | Application Note |
|---|---|---|
| AmpliSeq for Illumina Focus Panel | Targeted DNA/RNA research panel | Investigates 52 genes with known relevance to solid tumors |
| AmpliSeq for Illumina Cancer HotSpot Panel v2 | Targeted research panel | Interrogates hotspot regions of 50 cancer-associated genes |
| AmpliSeq for Illumina Comprehensive Cancer Panel | Targeted research panel | Sequences exonic regions of 409 cancer-associated genes |
| Infinium FFPE DNA Restoration Solution | DNA repair solution | Restores damaged DNA from FFPE samples for genotyping |
| TruSight Oncology 500 | Multi-variant assay | Analyzes TMB and MSI from low-quality FFPE samples |
| DesignStudio Assay Design Tool | Custom panel design | Enables creation of custom AmpliSeq panels for specific targets |
The AmpliSeq for Illumina product line offers both ready-to-use and customizable panels for targeted resequencing applications [16]. These panels are specifically optimized to work with low-input DNA samples, making them particularly suitable for FFPE specimens where DNA quantity and quality are often limiting factors [28]. The Infinium FFPE DNA Restoration Solution addresses the unique challenges of FFPE-derived DNA by repairing damage caused by formalin fixation, thereby improving downstream genotyping success rates [28].
For researchers investigating specific gene sets not covered by pre-designed panels, the DesignStudio Assay Design Tool provides a free, web-based platform for creating custom AmpliSeq for Illumina panels [16]. This flexibility enables the development of targeted sequencing approaches optimized for specific research questions, particularly valuable for FFPE samples where comprehensive sequencing may be challenged by DNA degradation. The TruSight Oncology 500 represents a comprehensive solution for oncology research, capable of analyzing multiple variant types—including tumor mutational burden (TMB) and microsatellite instability (MSI)—even from challenging FFPE samples [28].
The compatibility of AmpliSeq for Illumina technology with the MiSeq, NextSeq, and iSeq sequencing platforms provides researchers with a flexible framework for targeted genomic studies of FFPE specimens. Each platform offers distinct advantages: the iSeq 100 System delivers rapid turnaround for small-scale projects, the MiSeq Series provides longer read lengths ideal for amplicon sequencing, and the NextSeq Series enables high-throughput processing for large-scale studies [36] [40]. As research on FFPE samples continues to expand, particularly in oncology and biomarker discovery, understanding these platform characteristics becomes essential for designing efficient, cost-effective sequencing strategies that yield publication-quality data while addressing the unique challenges of degraded, cross-linked DNA.
Formalin-fixed, paraffin-embedded (FFPE) tissues are invaluable for clinical research, but the DNA derived from them presents significant challenges for next-generation sequencing (NGS). These samples are characterized by fragmentation, cross-linking, and formalin-induced artifacts such as cytosine deamination, which lead to a high number of false-positive variant calls [44] [45]. Effective downstream analysis requires specialized bioinformatics pipelines to distinguish these technical artifacts from true biological variants. This note details standardized protocols for variant calling specifically optimized for libraries prepared using the AmpliSeq for Illumina Direct FFPE DNA protocol, which enables library construction from slide-mounted FFPE tissues without prior deparaffinization or DNA purification [19] [46] [47].
Understanding FFPE-Derived NGS Data and Its Challenges
The integrity of DNA from FFPE samples is compromised by the fixation process, introducing specific biases and artifacts into sequencing data.
- DNA Fragmentation and Short Insert Size: DNA from FFPE samples is highly fragmented, resulting in sequencing libraries with a significantly shorter average insert size compared to matched fresh-frozen (FF) samples [45].
- Artifact Mutational Signature: The most predominant artifact is a specific pattern of C>T and G>A substitutions, resulting from cytosine deamination [44]. One study found that over 90% of unique FFPE calls were artifacts sharing this signature, and they were predominantly found at low allelic frequencies (<5%) [44].
- Artifact Chimeric Reads for SVs: FFPE processing can generate single-stranded DNA that randomly self-assembles via short reverse-complementary regions. This creates artifact chimeric reads, which are misinterpreted as evidence for structural variants (SVs), leading to a high false-positive SV rate [48].
A Standardized Workflow for Variant Calling from FFPE Libraries
A robust, multi-stage bioinformatics workflow is essential to mitigate these challenges. The following workflow is designed for data generated from the AmpliSeq for Illumina Direct FFPE DNA protocol.
Diagram 1: Bioinformatic workflow for FFPE variant calling.
Experimental Protocols for Key Analyses
Protocol for SNV and Indel Calling
This protocol is adapted from best practices for targeted sequencing data, such as that generated by AmpliSeq panels [49] [44].
- Step 1: Read Alignment and BAM Processing
- Tool: BWA-MEM or DRAGEN. The DRAGEN platform uses a pangenome reference for improved mapping and can process a 35x WGS sample in ~8 minutes [50].
- Processing Steps:
- Mark Duplicates: Identify and mark PCR duplicates to prevent false inflation of variant support.
- Base Quality Score Recalibration (BQSR): Correct for systematic errors in base quality scores using known variant sites [49].
- Step 2: Variant Calling
- Tool: GATK Mutect2 or DRAGEN SNV/indel caller. DRAGEN employs a de Bruijn graph assembler and a hidden Markov model, followed by a machine learning rescoring step to reduce false positives [50].
- Step 3: FFPE-Specific Filtering
- Approach: Apply a combination of hard filters and advanced models.
- Hard Filtering: Filter variants based on strand bias (e.g., FS > 30.0) and low allele frequency (e.g., AF < 0.05) [49] [44].
- AI-Based Filtering: Use a tool like DEEPOMICS FFPE, a deep neural network model trained on paired FF-FFPE data. It uses 41 discriminating features to remove artifacts while retaining true low-frequency variants with high accuracy (99.6% artifacts removed, 87.1% true variants maintained) [45].
- Approach: Apply a combination of hard filters and advanced models.
Protocol for Structural Variant (SV) Calling
Standard SV callers perform poorly on FFPE data due to artifact chimeric reads [48].
- Step 1: Pre-Filtration of Artifact Chimeric Reads
- Tool: FilterFFPE. This R package filters sequencing data to remove artifact chimeric reads (ACRs) prior to SV calling.
- Method: FilterFFPE identifies and removes ACRs characterized by specific properties, such as the length distribution of their short reverse-complementary regions [48].
- Step 2: SV Calling and Performance Evaluation
- Tools: Use standard callers like Manta, Delly, or Lumpy on the filtered BAM file.
- Validation: After applying FilterFFPE, the mean positive predictive value (PPV) for SV calling improved from 0.27 to 0.48 in simulated samples and from 0.11 to 0.27 in real FFPE samples, while sensitivity was maintained [48].
Performance Metrics and Validation
The following tables summarize key performance indicators for the described methods.
Table 1: Performance of SNV/Indel Filtering Tools on FFPE WES Data
| Tool / Metric | Specificity | Sensitivity | F1-Score | Key Advantage |
|---|---|---|---|---|
| DEEPOMICS FFPE [45] | 0.996 | 0.871 | 0.883 | AI model effective on low-AF variants |
| MuTect Filter [45] | ~0.407 | 0.969 | Low | Removes only a portion of artifacts |
| AF ≤ 5% Filter [44] | High | Very Low | N/A | Aggressive; removes true subclonal variants |
Table 2: Impact of Pre-Filtration on SV Calling in FFPE Samples
| Sample Type | SV Caller | Mean PPV (No Filter) | Mean PPV (With FilterFFPE) |
|---|---|---|---|
| Simulated WGS [48] | Delly, Lumpy, Manta | 0.27 | 0.48 |
| Real WES [48] | Delly, Lumpy, Manta | 0.11 | 0.27 |
The Scientist's Toolkit: Research Reagent Solutions
A successful experiment relies on integrated wet-lab and bioinformatics solutions. The following reagents and software are essential for the AmpliSeq for Illumina Direct FFPE DNA workflow.
Table 3: Essential Research Reagents and Software
| Item | Function | Specific Example |
|---|---|---|
| Direct FFPE DNA Kit | Library construction from slide-mounted FFPE tissue without DNA purification. | AmpliSeq for Illumina Direct FFPE DNA [19] [47] |
| Targeted Panel | Focuses sequencing on genes of interest, enabling high coverage from low-input, degraded DNA. | AmpliSeq for Illumina On-Demand Panels [46] |
| Library Prep Kit | Provides reagents for PCR-based library construction from amplicons. | AmpliSeq Library PLUS for Illumina [46] |
| Bioinformatics Platform | Provides accelerated, accurate secondary analysis for mapping and variant calling. | DRAGEN Platform [50] [51] |
| FFPE Filtering Software | Specialized tool for removing FFPE-specific artifacts from variant calls. | DEEPOMICS FFPE [45] |
Accurate variant calling from FFPE-derived libraries necessitates a dedicated bioinformatics strategy that addresses the unique artifacts introduced during sample preservation. By integrating the AmpliSeq for Illumina Direct FFPE DNA protocol with a robust downstream pipeline—featuring advanced alignment, variant calling, and specialized filtering tools like DEEPOMICS FFPE and FilterFFPE—researchers can significantly improve reliability, confidently identifying true variants amidst the noise. This structured approach ensures that the vast resource of archived FFPE tissues can be leveraged effectively for precision medicine and oncology research.
Troubleshooting the Direct FFPE DNA Workflow: Maximizing Success with Challenging Samples
The AmpliSeq for Illumina Direct FFPE DNA protocol provides a significant advantage for genomic research by enabling library construction from formalin-fixed paraffin-embedded (FFPE) tissues without the need for deparaffinization or DNA purification [47]. However, the inherent nature of archival FFPE samples presents substantial challenges, as they generally yield highly degraded and damaged DNA that performs poorly in downstream applications [52]. Implementing rigorous quality control (QC) measures before proceeding with sequencing is therefore economically and scientifically essential. This application note establishes comprehensive pre-assessment QC recommendations for FFPE samples, with particular emphasis on interpreting quantification cycle (Cq) values and their derivatives within the context of the AmpliSeq workflow. By adopting these standardized protocols, researchers can significantly improve sequencing success rates, data quality, and the reliability of conclusions drawn from these invaluable clinical specimens.
Essential Quality Control Metrics for FFPE Samples
Quality control for FFPE samples involves assessing both the extracted nucleic acids and the libraries prepared from them. The following thresholds are derived from empirical studies and product specifications to guide researchers in evaluating sample viability.
Table 1: Recommended QC Thresholds for FFPE Samples in RNA-Seq
| QC Metric | Recommended Minimum | Failed Sample Typical Value | Importance |
|---|---|---|---|
| RNA Concentration | 25 ng/μL [53] | 18.9 ng/μL [53] | Indicates sufficient starting material |
| Pre-capture Library Qubit Value | 1.7 ng/μL [53] | 2.08 ng/μL [53] | Reflects successful library construction |
| Reads Mapped to Gene Regions | 25 Million [53] | < 25 Million [53] | Ensures adequate data generation |
| Number of Detected Genes (TPM > 4) | 11,400 [53] | < 11,400 [53] | Measures gene detection sensitivity |
| Sample-wise Correlation | 0.75 (Spearman) [53] | < 0.75 [53] | Induces sample quality and reproducibility |
For DNA-based AmpliSeq panels, such as the TCR beta-SR Panel or On-Demand panels, the recommended input quantity is as low as 1-100 ng of DNA [47] [46]. The Illumina FFPE QC Kit utilizes a real-time PCR assay to evaluate DNA quality before restoration, helping to predict which samples are likely to succeed in subsequent array-based or sequencing applications [52]. Samples that pass this QC threshold are then eligible for restoration using the Infinium HD FFPE DNA Restore Kit, which repairs degraded DNA to an amplifiable state [52].
Fundamentals of Cq and ∆Cq Analysis in QC Workflows
The Quantification Cycle (Cq) is the fractional number of PCR cycles required for the amplification curve to cross a predefined fluorescence threshold [54]. It is fundamentally related to the starting concentration of the target molecule ( [54]). The lower the Cq value, the higher the initial concentration of the target template. The Cq value is not an absolute measurement but is dependent on several factors, including PCR efficiency and the level of the quantification threshold, making it crucial to interpret Cq values within the context of these parameters [54].
The difference in Cq values between two targets, or ∆Cq, is frequently used to calculate ratios of target concentration. For QC applications, this can be used to assess sample integrity by comparing the amplification of longer vs. shorter amplicons, or target genes vs. reference controls. The mathematical relationship is expressed as:
Diagram 1: The ∆∆Cq Calculation Workflow.
The core formula for the relationship between Cq and starting quantity is: ( Cq = \frac{\log(Nq) - \log(N0)}{\log(E)} ) Where ( Nq ) is the quantity at threshold, ( N0 ) is the starting quantity, and ( E ) is the PCR efficiency (fold-increase per cycle) [54].
From this, the gene expression or concentration ratio can be derived as: ( \text{Ratio} = E^{-\Delta Cq} ) [54]
For the double delta Ct analysis method, which is common in QC workflows to normalize data, the fold change is calculated as ( 2^{-\Delta\Delta Cq} ) [55]. A fold change of 1 indicates no difference from the control, values above 1 indicate upregulation or higher concentration, and values below 1 indicate downregulation or lower concentration [55].
Detailed Experimental Protocols
Pre-Sequencing QC Protocol for FFPE-Derived Nucleic Acids
This protocol is adapted from best practices for the AmpliSeq for Illumina Direct FFPE DNA and related workflows [47] [53] [52].
Materials Required:
- Extracted DNA/RNA from FFPE tissue sections
- Qubit Fluorometer and relevant assay kits (e.g., Qubit dsDNA HS Assay)
- Illumina FFPE QC Kit (for DNA) or equivalent RT-PCR assays [52]
- Real-Time PCR System and compatible reagents
- AmpliSeq for Illumina Library PLUS [47] [46]
- AmpliSeq for Illumina CD Indexes [47] [46]
Procedure:
- Nucleic Acid Quantification: Quantify the extracted DNA or RNA using a fluorometric method (e.g., Qubit). For RNA-seq from FFPE breast tissue, a minimum concentration of 25 ng/μL is recommended. Samples with concentrations below this threshold have a significantly higher risk of failure [53].
- Quality Assessment via qPCR: Perform a real-time PCR QC assay, such as the one provided in the Illumina FFPE QC Kit.
- Use 1-10 ng of input DNA per reaction.
- Run samples in triplicate to assess technical variability.
- Record Cq values for further analysis. A significant delay in Cq (e.g., > 2 cycles compared to a high-quality control sample) may indicate excessive degradation.
- Library Preparation & QC: Proceed with library preparation using the AmpliSeq for Illumina Direct FFPE DNA protocol and the appropriate panel (e.g., TCR beta-SR). Following preparation, quantify the final library using Qubit. A pre-capture library Qubit value of at least 1.7 ng/μL is recommended to ensure adequate yield for sequencing [53].
- Decision Point: Samples passing the above thresholds can be advanced to sequencing. Failed samples should be re-extracted or excluded.
Protocol for Interpreting ∆Cq in QC Context
This protocol outlines how to use Cq values derived from QC steps to make informed decisions about sample quality.
Procedure:
- Data Collection: Collect Cq values from the QC qPCR assay for both the target region (e.g., a short amplicon vs. a long amplicon to assess degradation) and a reference control.
- Calculate ∆Cq: For each sample, calculate ∆Cq as follows: ( \Delta Cq = Cq{\text{target}} - Cq{\text{reference}} ) In degradation assays, the "target" would be a long amplicon and the "reference" would be a short amplicon. A large, positive ∆Cq suggests the sample is degraded, as the long amplicon is poorly amplified compared to the short one.
- Establish a Baseline: Using a set of known high-quality samples, calculate the average ∆Cq to establish a baseline for a non-degraded sample.
- Interpret Results: Compare the ∆Cq of test samples to the baseline. A ∆Cq that is significantly larger than the baseline indicates sample degradation. The precise threshold for failure should be determined empirically for each assay and lab.
Integrated FFPE QC and Data Analysis Workflow
The following diagram illustrates the complete pathway from sample receipt to a data-ready library, integrating critical QC checkpoints and the logical flow of Cq-based decision-making.
Diagram 2: Integrated FFPE QC and Analysis Workflow.
Research Reagent Solutions for FFPE QC
The following table details key products and their roles in the FFPE QC and library preparation workflow.
Table 2: Essential Research Reagents for FFPE QC and Sequencing
| Product Name | Function | Specifications | Compatibility |
|---|---|---|---|
| AmpliSeq for Illumina Direct FFPE DNA [47] | Prepares DNA from slide-mounted FFPE tissues for library construction without deparaffinization or purification. | 24 reactions [47] | AmpliSeq for Illumina panels |
| Infinium FFPE QC Kit [52] | Uses real-time PCR to evaluate the quality of prospective DNA samples before restoration. | 384 reactions; includes primers and DNA template [52] | Human samples for Infinium arrays |
| Infinium HD FFPE DNA Restore Kit [52] | Restores degraded FFPE DNA to an amplifiable state for use in array-based applications. | 24 samples [52] | Samples from any species |
| AmpliSeq for Illumina Library PLUS [47] [46] | Reagents for preparing sequencing libraries. | 24, 96, or 384 reactions [47] [46] | AmpliSeq for Illumina panels |
| AmpliSeq for Illumina TCR beta-SR Panel [47] | Targeted panel for sequencing T cell receptor beta chain rearrangements from DNA/RNA. | Input: 1 ng; Targets CDR3 region [47] | DNA, RNA from FFPE, blood, tissue |
Formalin-fixed, paraffin-embedded (FFPE) samples represent an invaluable resource for cancer research and diagnostic development, but they present significant challenges for next-generation sequencing (NGS). The formalin fixation process causes chemical modifications of DNA and creates crosslinks between nucleic acids and proteins, while the paraffin embedding process introduces physical damage to DNA through heat and dehydration [56]. These processes result in highly degraded DNA with low yields, non-uniform ends, and various types of DNA damage including cytosine deamination (leading to C to T mutations) and oxidative damage (leading to G to T mutations) [56]. The AmpliSeq for Illumina Direct FFPE DNA protocol is specifically designed to address these challenges by enabling library preparation from unstained, slide-mounted FFPE tissues without requiring deparaffinization or DNA purification, thereby streamlining the workflow and reducing sample loss [18].
For researchers and drug development professionals, maintaining assay sensitivity and accuracy is paramount when working with these precious clinical samples. The key issues of low library yield and poor sequencing performance often stem from the compromised nature of FFPE-derived DNA, which can lead to inadequate library complexity, sequencing artifacts, and false-positive variant calls [56] [57]. Understanding and addressing these challenges through optimized protocols is essential for generating reliable data that can inform therapeutic development and clinical decision-making.
Understanding FFPE-Specific Challenges and Their Impact on Data Quality
Mechanisms of DNA Damage in FFPE Samples
The preservation process that makes FFPE samples stable for long-term room temperature storage simultaneously introduces multiple types of DNA damage that profoundly impact sequencing performance. The crosslinking between nucleic acids and proteins not only makes DNA extraction difficult but also creates physical barriers to polymerase progression during amplification [56]. Additionally, single-stranded overhangs from fragmented DNA can anneal with other DNA fragments during library preparation, leading to chimeric reads during sequencing that complicate accurate variant calling [56].
The most insidious challenges arise from base-level damage that introduces sequencing artifacts which can be misinterpreted as genuine mutations in patient samples. Cytosine deamination converts cytosine to uracil, resulting in C to T mutations during sequencing, while oxidative damage creates lesions such as 8-oxo G, which leads to G to T mutations [56]. These artifacts are particularly problematic in cancer research, where identifying true somatic mutations is critical for therapeutic targeting.
Impact of Low Input DNA on Library Complexity and Variant Detection
Library complexity, defined as the number of unique DNA molecules represented in the library, is fundamentally constrained by the original template molecules present in the input DNA [57]. When DNA input is reduced, particularly common with FFPE samples where material is often limited, the resulting libraries suffer from reduced unique coverage despite high total read counts. This occurs because PCR amplification during library construction can generate an unlimited amount of product from limited input but cannot create more information than was present in the original template [57].
The relationship between input DNA, library complexity, and variant detection sensitivity is non-linear and can lead to substantial technical variability. Fluctuations in library complexity complicate variant detection using both standardized and clinical specimens, often resulting in technical replicates with vastly different estimates of variant allelic fraction [57]. This variability poses significant challenges for drug development professionals who require consistent and accurate mutation profiling across sample batches.
Table 1: Common FFPE DNA Damage Types and Their Impact on Sequencing
| Damage Type | Cause | Impact on Sequencing | Resulting Artifact |
|---|---|---|---|
| Cytosine deamination | Formalin fixation, prolonged storage | Incorrect base incorporation | C to T mutations |
| Oxidative damage | Sample processing, storage conditions | Erroneous base calling | G to T mutations |
| DNA crosslinks | Formalin fixation | Polymerase blockage, fragmented sequences | Reduced coverage, sequencing failures |
| Nicked DNA | Paraffin embedding heat exposure, enzymatic degradation | Non-uniform ends, fragmented sequences | Incomplete sequencing reads |
| Abasic sites | Chemical degradation | Polymerase blockage, sequence termination | Coverage dropouts |
Optimized Methodologies for Improved Library Yield and Sequencing Performance
AmpliSeq for Illumina Direct FFPE DNA Workflow
The AmpliSeq for Illumina Direct FFPE DNA protocol employs a specialized approach designed specifically to overcome the limitations of FFPE samples. The workflow begins with direct sampling from unstained, slide-mounted FFPE tissues, eliminating the need for deparaffinization or DNA purification that can further degrade already compromised samples [18]. This approach significantly reduces sample loss and processing time, making it particularly valuable when working with precious clinical specimens where material is limited.
The core of the protocol utilizes a multiplex PCR-based workflow that replaces nonspecific hybridization steps, resulting in high-specificity, high-uniformity amplified libraries [18]. This targeted approach is especially advantageous for FFPE samples because small amplicons are more successful than probe-based capture methods with fragmented DNA [58]. The protocol accommodates input quantities ranging from 1-100 ng, with 10 ng recommended per pool, providing flexibility for samples with varying degrees of DNA preservation [18]. The entire library preparation requires approximately 5 hours with only 1.5 hours of hands-on time, enabling rapid processing of multiple samples [18].
DNA Repair and Fragmentation Strategies
Advanced DNA repair strategies are essential for handling the specific damage types present in FFPE-derived DNA. Specialized repair enzymes can selectively target damaged DNA bases, excising damaged portions when single-stranded damage is detected and employing base excision repair mechanisms for double-strand damage [56]. This approach significantly enhances data accuracy by removing artifacts resulting from damaged sites while preserving true mutations that appear on both DNA strands [56].
An innovative aspect of modern FFPE workflows involves integrating repair with fragmentation. Repairing nicks and gaps before fragmentation helps maintain the DNA's original fragment size and prevents further size reduction during fragmentation [56]. Additionally, filling in single-stranded overhangs that lack damage retains intact DNA for incorporation into the library, which would otherwise be lost, thereby improving sequencing coverage [56]. This integrated repair-fragmentation approach is particularly valuable as it prevents the propagation of sequencing artifacts that can occur when polymerase activity precedes damaged base removal [56].
Diagram 1: AmpliSeq Direct FFPE DNA Protocol Workflow. This diagram illustrates the streamlined workflow from FFPE tissue sections to sequencing-ready libraries, highlighting key steps that address FFPE-specific challenges.
Quality Control and Library Quantification
Robust quality control measures are essential throughout the FFPE library preparation process. Prior to library construction, sample quality assessment helps determine whether FFPE samples are viable input material [28]. The AmpliSeq for Illumina platform incorporates library equalization techniques that normalize libraries, improving sequencing efficiency and data balance across samples [18]. For sequencing, unique molecular identifiers (UMIs) provide error correction and accuracy, reducing false-positive variant calls while increasing variant detection sensitivity [59].
The impact of reduced DNA input on library complexity necessitates careful monitoring of unique versus duplicate read percentages during sequencing data analysis. At high sequencing depths, unique and total (unique plus duplicate) read coverage are not well correlated, so simply increasing the number of sequenced reads does not necessarily improve sensitivity [57]. Tracking depth of coverage with unique reads is essential for clinical NGS to ensure that sensitivity and accuracy are maintained, particularly for detecting low-frequency variants in heterogeneous tumor samples [57].
Essential Reagents and Tools for Successful FFPE Sequencing
Table 2: Research Reagent Solutions for AmpliSeq FFPE Workflows
| Reagent/Tool | Function | Specifications | Application Notes |
|---|---|---|---|
| AmpliSeq for Illumina Direct FFPE DNA | Direct library prep from FFPE tissues | 24 reactions, no purification needed | Enables direct sampling from slide-mounted FFPE tissues |
| AmpliSeq Library PLUS | Library preparation core reagents | 24, 96, or 384 reactions | Multiplex PCR-based workflow with <1.5 hours hands-on time |
| AmpliSeq CD Indexes | Sample multiplexing | 96 indexes per set | Enables pooling of multiple samples for cost-effective sequencing |
| AmpliSeq Custom DNA Panels | Targeted content investigation | 12 to 12,288 amplicons | DesignStudio tool for custom panel design |
| DNA Repair Mixes | Fix FFPE-specific DNA damage | Targets cytosine deamination, oxidative damage | Critical for reducing sequencing artifacts and false positives |
| Library Equalizer | Normalization of library concentrations | Beads and reagents for normalization | Ensures balanced representation in pooled sequencing |
The AmpliSeq for Illumina Direct FFPE DNA protocol represents a significant advancement in addressing the persistent challenges of low library yield and poor sequencing performance from FFPE samples. By integrating direct sampling without purification, specialized DNA damage repair, and multiplex PCR with small amplicons, this approach enables researchers to extract high-quality genetic information from even highly degraded specimens. The implementation of repair enzymes that selectively target FFPE-specific damage while preserving true mutations has been particularly instrumental in reducing false positives and improving variant calling accuracy.
For drug development professionals and clinical researchers, these advancements translate to more reliable data from precious clinical archives, enabling comprehensive retrospective studies and expanding the potential of precision medicine initiatives. As NGS technologies continue to evolve, further innovations in enzymatic fragmentation, damage repair specificity, and library complexity preservation will continue to enhance our ability to unlock the valuable genetic information preserved in FFPE samples across decades of clinical practice.
The molecular analysis of bone tissue presents significant challenges due to its mineralized nature, which necessitates decalcification prior to processing. For researchers utilizing the AmpliSeq for Illumina Direct FFPE DNA protocol, maintaining nucleic acid integrity throughout decalcification is paramount for successful next-generation sequencing (NGS). This application note details optimized EDTA-based decalcification strategies that preserve DNA quality and quantity, enabling reliable genetic analysis from formalin-fixed paraffin-embedded (FFPE) bone specimens without requiring additional purification steps. Evidence confirms that EDTA-decalcified FFPE tissue shows comparable NGS performance to non-decalcified samples, achieving similar sequencing success rates (90.3% vs 91.0% optimal coverage) despite slightly lower DNA yields [60].
EDTA Versus Acidic Decalcifiers: Mechanisms and Molecular Preservation
Fundamental Mechanisms of Action
Decalcifying agents function through distinct biochemical mechanisms that directly impact molecular preservation:
- EDTA (Chelating Agent): EDTA gently removes calcium ions through chelation, forming soluble complexes with calcium cations in hydroxyapatite crystals without damaging the organic matrix. This mechanism preserves tissue morphology, antigenicity, and nucleic acid integrity for subsequent analysis [61] [62].
- Strong Mineral Acids (Nitric Acid, Hydrochloric Acid): These acids rapidly dissolve mineral content through protonation of phosphate groups but cause excessive demineralization, resulting in tissue damage, antigen masking, and nucleic acid degradation when applied too long [61] [63].
- Weak Organic Acids (Formic Acid, Trichloroacetic Acid): These offer intermediate decalcification rates with moderate tissue preservation effects, though they still pose risks to biomolecules compared to EDTA [61].
Quantitative Comparison of Decalcifier Performance
The table below summarizes the documented performance of various decalcification methods across key parameters relevant to NGS applications:
Table 1: Comprehensive Comparison of Decalcification Methods for Molecular Analysis
| Decalcification Method | Decalcification Speed | Tissue Morphology Preservation | DNA/RNA Preservation | Compatibility with AmpliSeq |
|---|---|---|---|---|
| EDTA (Standard) | Slow (7 days for 5mm samples) [63] | Excellent [61] [62] | Optimal for DNA/RNA [62] [64] | High [60] |
| Accelerated EDTA | Moderate (24-48h for mouse bones) [62] | Excellent [62] | Superior mRNA preservation [62] | Expected High |
| Nitric Acid (5%) | Fast (3-8h for 5mm samples) [63] | Poor to Moderate [61] [63] | Substantial degradation [61] | Low |
| Formic Acid (5-8%) | Moderate (24-72h) [61] | Moderate [61] [64] | Variable; often degraded [64] | Low to Moderate |
| Hydrochloric Acid (5%) | Fast (5-8h for 5mm samples) [63] | Poor [63] [60] | Severe degradation [60] | Very Low |
Accelerated EDTA Decalcification Protocol
Hypertonic Saline- and Detergent-Accelerated EDTA Method
Recent research demonstrates that EDTA decalcification can be significantly accelerated without compromising molecular integrity through optimized additive formulations [62]:
Figure 1: Workflow for preparing and using accelerated EDTA decalcification solution. The combination of hypertonic saline and detergents enhances penetration while maintaining biomolecular integrity.
Step-by-Step Protocol
Solution Preparation:
- Prepare 26% EDTA (w/v) in distilled water
- Add NaCl to 5% final concentration
- Add Tween-20 (0.5% v/v) and Triton X-100 (1% v/v)
- Adjust pH to 7.4 using NaOH and verify complete dissolution
Tissue Processing:
- Fix bone specimens in 4% paraformaldehyde for 24-48 hours
- Transfer to 50mL accelerated EDTA solution
- Incubate at 45°C with constant agitation
- Change solution every 12 hours for optimal results
Endpoint Determination:
- Confirm complete decalcification when bones become pliable
- Verify using physical testing (needle penetration) or chemical testing (calcium oxalate method) [63]
- Process through standard FFPE protocol without neutralization
This optimized method reduces decalcification time from 7 days to 24-48 hours for mouse long bones while better preserving mRNA compared to standard EDTA at room temperature [62].
Integration with AmpliSeq for Illumina Direct FFPE DNA Workflow
Comprehensive Workflow from Specimen to Sequencing
The diagram below illustrates the complete integrated workflow from bone decalcification through to sequencing using the AmpliSeq for Illumina Direct FFPE DNA protocol:
Figure 2: Complete integrated workflow from bone specimen to sequencing analysis, highlighting the compatibility between optimized EDTA decalcification and the AmpliSeq for Illumina Direct FFPE DNA protocol.
DNA Quality Assessment and QC Metrics
Rigorous quality control is essential for successful NGS from decalcified specimens. The following metrics should be evaluated:
Table 2: DNA Quality Metrics for EDTA-Decalcified vs. Non-Decalcified FFPE Samples
| Quality Parameter | EDTA-Decalcified Samples | Non-Decalcified Samples | Statistical Significance |
|---|---|---|---|
| Qubit DNA Concentration (ng/μL) | 31.60 (IQR: 16.09-60.50) [60] | 37.00 (IQR: 18.14-66.80) [60] | p = 0.4 |
| NanoDrop DNA Concentration (ng/μL) | 116.80 (IQR: 63.70-178.05) [60] | 180.40 (IQR: 88.30-343.60) [60] | p = 0.006 |
| NanoDrop 260/280 Ratio | 1.89 (IQR: 1.86-1.93) [60] | 1.90 (IQR: 1.87-1.92) [60] | p = 0.8 |
| NanoDrop 260/230 Ratio | 1.86 (IQR: 1.53-2.06) [60] | 2.02 (IQR: 1.72-2.21) [60] | p = 0.002 |
| Suboptimal Sequencing Rate | 9.7% [60] | 9.0% [60] | p = 0.9 |
Research Reagent Solutions
The table below details essential reagents and their functions for implementing optimized EDTA decalcification protocols:
Table 3: Essential Research Reagents for EDTA-Based Decalcification Protocols
| Reagent | Function | Optimal Concentration | Notes |
|---|---|---|---|
| EDTA Disodium Salt | Calcium chelation, mineral removal | 15-26% (w/v) [62] [63] | Higher concentrations accelerate process |
| Sodium Chloride (NaCl) | Charge shielding, enhances EDTA penetration | 5% (w/v) [62] | Hypertonic concentration masks electric charges |
| Tween-20 | Detergent, removes hydrophobic barriers | 0.5% (v/v) [62] | Enhances tissue permeability |
| Triton X-100 | Non-ionic surfactant, delipidation | 1% (v/v) [62] | Removes lipid barriers in tissue matrix |
| Osteosoft (Commercial EDTA) | Standardized decalcification | Manufacturer's instructions [60] | Consistent performance for clinical samples |
| NaOH | pH adjustment | As needed for pH 7.4 [63] | Maintains neutral pH for biomolecule preservation |
Technical Considerations and Troubleshooting
Optimal Duration and Tissue Specifications
The decalcification time must be optimized for specific tissue types and sizes:
- Mouse long bones: 24 hours provides optimal preservation for subsequent biophotonic analysis [61]
- 5mm bone biopsies: 2-4 days depending on bone density [60]
- Mouse ankle joints: 24 hours with accelerated EDTA method [62]
- Rodent incisor teeth: ACD decalcification buffer or Morse's solution better preserved RNA for RNAscope [64]
Impact on Downstream Molecular Applications
- Immunofluorescence: EDTA optimally preserves antigenicity compared to acidic decalcifiers [61] [62]
- RNA Analysis: Accelerated EDTA method better preserves mRNA compared to standard protocols [62]
- NGS Performance: EDTA-decalcified samples show mutation detection consistent with known tumor profiles [60]
Optimized EDTA-based decalcification protocols, particularly the accelerated method incorporating hypertonic saline and detergents, provide an optimal balance between processing time and molecular preservation. When integrated with the AmpliSeq for Illumina Direct FFPE DNA protocol, these methods enable reliable genetic analysis from challenging bone specimens without additional purification requirements. The strategies outlined herein empower researchers and drug development professionals to maximize the utility of bone samples in precision medicine initiatives, ultimately supporting more comprehensive molecular profiling from limited specimen types.
The analysis of degraded DNA, particularly from formalin-fixed, paraffin-embedded (FFPE) tissues, presents significant challenges for researchers utilizing targeted next-generation sequencing (NGS) approaches such as the AmpliSeq for Illumina Direct FFPE DNA protocol. FFPE preservation induces DNA fragmentation and crosslinking through formalin-induced chemical modifications, substantially reducing nucleic acid integrity and amplifiability [65] [66]. This degradation manifests as reduced library preparation efficiency, impaired amplification performance, and potential introduction of sequencing artifacts that compromise data reliability.
The AmpliSeq for Illumina technology enables targeted sequencing through highly multiplexed PCR amplification, making it particularly valuable for analyzing degraded samples when appropriate quality control and input DNA adjustments are implemented [46]. However, successful application requires careful balancing of input DNA quantity with quality metrics to optimize coverage uniformity and variant detection accuracy. This protocol outlines a standardized framework for assessing DNA degradation and implementing corrective strategies to maximize sequencing success from compromised samples without additional purification steps.
Assessment of DNA Degradation Status
Quantitative PCR for Integrity Evaluation
Quantitative PCR (qPCR) provides a robust method for evaluating DNA integrity by comparing amplification efficiency across targets of varying lengths. In degraded samples, shorter amplicons demonstrate preferential amplification compared to longer targets due to fragmentation. This principle can be leveraged using specialized qPCR assays specifically designed with differential amplicon sizes to calculate degradation ratios [67].
The experimental protocol involves:
- Reaction Setup: Prepare qPCR reactions using systems such as PowerQuant (Promega) or Plexor HY (Promega) according to manufacturer specifications with 1-5 μL of DNA extract [67].
- Target Amplification: Simultaneously amplify short and long targets (e.g., 84 bp vs. 294 bp for PowerQuant) using appropriate cycling conditions [67].
- Data Analysis: Calculate degradation ratios by comparing quantified values for short versus long targets. Samples with significant degradation show elevated ratios due to reduced amplification efficiency for longer targets [67].
For male FFPE samples, the [Auto]/[Y] ratio derived from Plexor HY system data (99 bp autosomal target versus 133 bp Y-chromosomal target) shows strong correlation (R = 0.75, p < 0.001) with dedicated degradation assessment methods, providing an alternative integrity measurement approach [67].
Gel Electrophoresis for Fragment Analysis
Gel electrophoresis enables direct visualization of DNA fragment size distribution, providing complementary information to qPCR-based methods. This technique is particularly valuable for identifying the extent of fragmentation in FFPE-derived DNA [66].
The standard protocol includes:
- Gel Preparation: Create 1% agarose gels by dissolving agarose powder in 1× TAE buffer with subsequent addition of GelRed dye at 1× concentration [66].
- Sample Loading: Mix 10 μL DNA samples with 2 μL of 6× loading buffer and load alongside appropriate molecular weight markers [66].
- Electrophoresis: Run at 100 V for 60 minutes in TAE buffer until sufficient migration occurs [66].
- Visualization: Document under UV light to assess fragmentation patterns; degraded samples appear as smears with predominant low molecular weight fragments [66].
Table 1: DNA Quality Assessment Methods and Interpretation
| Method | Parameters Measured | Indication of Degradation | Suitable Sample Types |
|---|---|---|---|
| qPCR Size Differential | Ratio of short:long target quantification | Elevated ratio values | FFPE tissues, forensic samples |
| Gel Electrophoresis | Fragment size distribution | Smear with predominant low molecular weight fragments | All DNA sample types |
| Spectrophotometry | OD 260/280 and 260/230 ratios | 260/280 < 1.8, 260/230 < 2.0 | High-quality DNA >20 ng/μL |
| Bioanalyzer/Femto Pulse | DNA Integrity Number (DIN) | DIN < 3.0 for FFPE samples | All DNA sample types |
Spectrophotometric and Fluorometric Quality Control
Nucleic acid purity and concentration measurements provide essential complementary data for assessing sample quality. The Nanodrop system evaluates purity through absorbance ratios, with optimal DNA demonstrating 260/280 ≈ 1.8 and 260/230 ≈ 2.0-2.2 [68]. Significant deviations from these values indicate contamination that may inhibit enzymatic reactions in library preparation. For accurate concentration measurement of degraded samples, fluorometric methods (Qubit with dsDNA BR Assay) are preferred over spectrophotometry due to superior specificity for double-stranded DNA and reduced susceptibility to contaminants [68].
DNA Input Adjustment Strategies
Input Mass and Molarity Considerations
Degraded DNA samples require careful input adjustment to compensate for reduced amplifiable templates while maintaining optimal reaction conditions. The recommended input for AmpliSeq for Illumina Direct FFPE DNA protocol ranges from 1-100 ng, with degradation status guiding precise quantity selection [46]. For severely compromised samples, increasing input mass within this range helps counterbalance the reduced fraction of amplifiable molecules.
Table 2: DNA Input Guidance Based on Fragment Size and Degradation Status
| Fragment Size Distribution | Recommended Input Mass | Recommended Input Molarity | AmpliSeq Panel Type |
|---|---|---|---|
| High molecular weight (>500 bp) | 10-30 ng | ~3-10 fmol | Standard panels |
| Moderately degraded (150-500 bp) | 30-60 ng | ~10-20 fmol | Standard panels |
| Severely degraded (<150 bp) | 60-100 ng | ~20-35 fmol | Custom small amplicon panels |
| cfDNA/FFPE dual use | 1-20 ng | Varies by size | HD panels (75-125 bp) |
For molar quantification, which is particularly relevant for fragmented samples, use the formula: Moles of DNA = (Mass in ng × 10^9) / (Base pairs × 660) This calculation enables standardized input regardless of fragmentation state, ensuring consistent library preparation performance [68].
Panel Design Optimization for Degraded DNA
The AmpliSeq technology supports panel customization to accommodate degraded samples through amplicon size reduction. For FFPE DNA analysis, AmpliSeq HD panels employ shorter amplicons (75-125 bp for cfDNA/FFPE dual use; 125-175 bp for FFPE-specific applications) to maximize target coverage across fragmented templates [7] [34]. When designing custom panels for degraded samples, prioritize:
- Amplicon size minimization (≤150 bp) to align with typical FFPE fragment lengths [65]
- Target region prioritization to maintain critical genomic regions within panel scope
- Pool balancing optimization to ensure uniform coverage across multiplexed reactions [34]
Enzymatic Repair of FFPE DNA
Enzymatic repair methods can partially reverse formalin-induced DNA damage, improving amplification efficiency and sequencing reliability. The PreCR Repair Mix (NEB) demonstrates efficacy in restoring DNA integrity through excision of deaminated cytosines and repair of oxidized bases [66].
The standard repair protocol includes:
- Reaction Assembly: Combine 1-100 ng FFPE DNA with repair buffer and enzyme mix according to manufacturer specifications
- Incubation: Conduct repair at appropriate temperature (typically 37°C) for 30-60 minutes
- Enzyme Inactivation: Heat-inactivate at specified temperature before proceeding to library preparation
- QC Verification: Assess repair efficacy through qPCR amplification comparison pre- and post-treatment
Post-repair evaluation of 26 SNP loci using targeted NGS demonstrates substantial improvements in amplification efficiency and reduced base substitution artifacts, particularly for samples with moderate degradation [66].
Workflow Integration and Quality Control
Comprehensive QC Framework Implementation
Implementing a standardized quality control framework enables effective stratification of FFPE samples according to degradation level, guiding appropriate resource allocation and methodological adjustments. This nanoscale QC approach integrates gel electrophoresis, qPCR, and NGS to create a comprehensive assessment pipeline [66].
The tiered decision framework includes:
- Sample categorization based on degradation metrics (qPCR ratios, fragment size distribution)
- High-integrity samples (minimal degradation) directed to standard workflows
- Moderately degraded samples selected for input mass adjustment or enzymatic repair
- Severely degraded samples routed to small-amplicon panels or alternative approaches
AmpliSeq for Illumina Direct FFPE DNA Protocol Modifications
The AmpliSeq for Illumina Direct FFPE DNA protocol enables library preparation from slide-mounted FFPE tissues without DNA purification, preserving sample integrity and streamlining workflow [46]. For degraded samples, implement these key modifications:
- Input mass adjustment based on prior QC assessment
- Extension of enzymatic treatment steps to enhance de-crosslinking
- Modified amplification cycles (increased for low-input degraded samples)
- Library quantification normalization to account for yield variations
This optimized approach maintains compatibility with Illumina sequencing systems (MiSeq, iSeq 100, NextSeq series) while improving performance with compromised samples [46].
Research Reagent Solutions
Table 3: Essential Research Reagents for Degraded DNA Analysis
| Reagent/Kit | Manufacturer | Primary Function | Application Note |
|---|---|---|---|
| AmpliSeq for Illumina Direct FFPE DNA | Illumina | Library preparation from unstained FFPE tissues without purification | Enables direct processing from tissue sections; 24 reactions [46] |
| AmpliSeq Library PLUS for Illumina | Illumina | Library construction reagents | Required for panel implementation; 24 or 96 reactions [46] |
| QIAamp DNA FFPE Tissue Kit | Qiagen | DNA extraction from FFPE samples | Standardized purification for challenging samples [66] |
| PowerQuant System | Promega | DNA quantification and degradation assessment | Simultaneously measures concentration and degradation index [67] |
| PreCR Repair Mix | NEB | Enzymatic repair of damaged DNA | Reduces formalin-induced artifacts; improves amplification [66] |
| Qubit dsDNA BR Assay | Thermo Fisher | Fluorometric DNA quantification | Specific double-stranded DNA measurement [68] |
| Plexor HY System | Promega | Human and male DNA quantification | Alternative degradation assessment via [Auto]/[Y] ratio [67] |
Workflow Visualization
FFPE DNA Quality Assessment and Input Adjustment Workflow
DNA Quality Assessment Methods Integration
Troubleshooting PCR Amplification and Library Normalization
Formalin-fixed paraffin-embedded (FFPE) tissue samples represent a critical resource for cancer and genetic disease research, yet they present significant challenges for next-generation sequencing (NGS) workflows. The AmpliSeq for Illumina Direct FFPE DNA protocol enables library preparation without requiring DNA purification, but this streamlined approach introduces specific complications in PCR amplification and downstream library normalization. The fixation process causes extensive nucleic acid fragmentation and introduces chemical modifications that reduce the number of templates available for amplification [15] [69]. When processing these challenging samples, researchers commonly encounter issues with low library yield, amplification bias, and normalization inaccuracies that can compromise sequencing results. This application note provides detailed methodologies for troubleshooting these critical steps, ensuring reliable data from even the most degraded FFPE samples.
PCR Amplification Troubleshooting
Common Amplification Failure Modes
PCR amplification of FFPE-derived DNA frequently manifests specific failure patterns that require distinct diagnostic approaches. Inhibitor carryover from fixation chemicals or paraffin can suppress polymerase activity, while extensive fragmentation reduces the number of amplifiable templates despite adequate spectrophotometric readings [70]. Additionally, sequence damage from formalin fixation creates lesions that block polymerase progression, resulting in incomplete amplicons. These issues collectively contribute to three primary failure modes: complete amplification failure (no products), suboptimal yield (insufficient for library construction), or non-specific amplification (multiple unintended products) [71].
Traditional DNA quantification methods exacerbate these issues by failing to distinguish between intact amplifiable templates and damaged DNA fragments. Studies demonstrate that spectrophotometric overestimation of functional DNA can reach three-fold compared to quantitative PCR methods specifically designed to measure amplifiable content [69]. This discrepancy leads to systematic under-loading of functional templates despite apparently adequate DNA input.
Systematic Troubleshooting Protocol
Assess Input DNA Quality: Utilize the Quantitative Functional Index (QFI) PCR method to determine amplifiable template concentration rather than relying solely on spectrophotometry [69]. Design QFI-PCR amplicons to match the size range of your target AmpliSeq panel (typically 100-150bp). For the AmpliSeq Direct FFPE DNA protocol, Illumina recommends using the Infinium FFPE QC Kit to determine ΔCq values, with samples exhibiting ΔCq ≤ 5 being optimal and those with ΔCq > 5 requiring increased input or potentially resulting in reduced assay performance [15].
Optimize Reaction Components:
- DNA Polymerase Selection: Use hot-start DNA polymerases specifically formulated for inhibited samples to prevent non-specific amplification and improve tolerance to common FFPE-derived inhibitors [71].
- Magnesium Concentration: Titrate Mg2+ concentration between 1.5-5.0 mM, as excessive magnesium promotes non-specific amplification while insufficient magnesium reduces yield [71] [72].
- Additives: Incorporate PCR enhancers such as betaine (0.5-2.5 M), DMSO (1-10%), or BSA (10-100 μg/mL) to mitigate the effects of secondary structure and contaminants [72].
Adjust Thermal Cycling Parameters:
- Denaturation: Increase denaturation time to 30-60 seconds to ensure complete separation of cross-linked DNA fragments common in FFPE samples [71].
- Annealing: Implement a gradient thermal cycler to optimize annealing temperature in 1-2°C increments, typically 3-5°C below the primer Tm [71] [72].
- Cycle Number: Increase PCR cycles to 12-17 for FFPE samples compared to standard protocols, as recommended for the "Amplify Tagmented DNA" step in the Illumina DNA Prep with Enrichment protocol [15].
Table 1: Troubleshooting Guide for PCR Amplification with Direct FFPE DNA
| Problem | Possible Causes | Recommended Solutions |
|---|---|---|
| No amplification | Severe DNA degradation, potent PCR inhibitors, insufficient functional templates | Implement QFI-PCR quantification [69], re-extract using dedicated FFPE kits [15], increase input DNA volume, add specialized enhancers |
| Low yield | Moderate DNA degradation, suboptimal cycling conditions, minor inhibitor carryover | Increase PCR cycles to 12-17 [15], optimize Mg2+ concentration, incorporate betaine or DMSO [72], verify primer quality |
| Non-specific products | Excessive DNA input, low annealing temperature, primer-dimer formation | Use hot-start polymerase [71], increase annealing temperature incrementally, optimize primer concentrations (0.1-1 μM) [71], reduce input DNA |
| High duplication rates | Insufficient template input, overamplification, limited library complexity | Increase functional DNA input based on QFI-PCR, reduce PCR cycles, optimize input using dilution series (e.g., 10-120 ng) [73] |
Experimental Protocol: Quantitative Functional Index (QFI) PCR
Purpose: To accurately quantify amplifiable DNA templates in FFPE samples [69].
Materials Required:
- Real-time PCR system (e.g., Bio-Rad CFX96)
- TaqMan Gene Expression Master Mix
- Custom TaqMan assay targeting 119bp TBP gene fragment
- High-quality genomic DNA standard (e.g., NA04025 cell line DNA)
- FFPE DNA samples normalized to 5 ng/μL
Methodology:
- Prepare a 5-fold serial dilution of high-quality genomic DNA standard (50 ng to 16 pg, representing 15,150 to 5 haploid genomes).
- Design primers and probe to amplify a 119 bp region of the TATA box binding protein (TBP) gene:
- Forward primer: 5′-CCA GAC TGG CAG CAA GAA AAT-3′ (900 nM)
- Reverse primer: 5′-CCT TAT AGG AAA CTT CAC ATC ACA GC-3′ (900 nM)
- TaqMan probe: 5′-VIC-TGC TAG AGT TGT ACA GAA GTT GGG TTT TCC AGC-TAMRA-3′ (250 nM) [69]
- Set up 11 μL reactions containing 1× Master Mix, primers and probe at indicated concentrations, and 5 ng of FFPE DNA.
- Run qPCR with cycling conditions: 95°C for 10 minutes, followed by 50 cycles of 95°C for 15 seconds and 60°C for 1 minute.
- Calculate the absolute copy number of amplifiable templates from the standard curve.
- Determine QFI as the percentage of amplifiable templates compared to the theoretical maximum (100% = 3,030 amplifiable copies from 10 ng input DNA) [69].
Interpretation: Samples with QFI < 5% require increased input or specialized restoration protocols before proceeding with library preparation.
Library Normalization Strategies
Normalization Challenges with FFPE-Derived Libraries
Library normalization presents particular difficulties for FFPE samples due to the inherent variability in amplification efficiency between samples with different levels of degradation. Traditional normalization methods based on total DNA concentration consistently fail because they cannot account for differences in amplifiability between samples [69] [70]. This results in sequencing lane imbalance, with some samples being over-represented while others are under-represented, ultimately reducing the effective sequencing depth and potentially causing sample dropouts.
Recent studies demonstrate that normalization errors account for up to 35% of failed sequencing runs in laboratories processing FFPE samples. The problem intensifies in high-throughput environments where manual normalization of 96-plex or 384-plex libraries introduces substantial technical variation [73]. Common symptoms of normalization failures include uneven coverage distribution, high coefficient of variation (>15%) in read counts across samples, and complete absence of data from individual samples despite successful library preparation.
Normalization Methodologies
Automated Normalization Systems: Implement iconPCR AutoNormalization technology which automatically adjusts amplification cycles based on real-time fluorescence monitoring, significantly reducing hands-on time and improving consistency [73]. The system offers three normalization approaches:
- Slope-based: Adjusts cycles based on the rate of fluorescence increase during exponential phase
- Target Fluorescence: Terminates reactions when a predefined fluorescence threshold is reached
- xBaseline: Calculates optimal cycles based on the crossing point relative to baseline fluorescence
Fluorescence-Based Pooling: For laboratories without access to automated normalization systems, implement Pooling by Fluorescence methods that use end-point RFU (Relative Fluorescence Unit) values to calculate pooling volumes rather than relying on post-amplification quantification [73]. This approach reduces the coefficient of variation in sample representation from >20% to <10% compared to volume-based pooling.
qPCR-Based Normalization: Use digital PCR or quantitative PCR with library-specific assays to precisely quantify amplifiable library molecules before pooling [69]. This method provides the most accurate normalization but requires additional processing time and specialized equipment.
Table 2: Comparison of Library Normalization Methods for Direct FFPE DNA Workflows
| Method | Principles | Hands-on Time | Expected %CV | Best For |
|---|---|---|---|---|
| AutoNormalization (iconPCR) | Real-time fluorescence monitoring with automatic cycle adjustment [73] | Low (30 min) | 5-8% | High-throughput labs processing >50 samples weekly |
| Pooling by Fluorescence | Uses endpoint RFU values to calculate pooling volumes [73] | Moderate (60 min) | 7-10% | Medium-throughput labs with standard real-time PCR systems |
| qPCR-Based Quantification | Library-specific qPCR assays to quantify amplifiable molecules [69] | High (90 min) | 3-5% | Low-throughput applications requiring maximum accuracy |
| Spectrophotometry/Fluorometry | Traditional methods based on total DNA concentration | Low (30 min) | 15-25% | Not recommended for FFPE samples |
Experimental Protocol: iconPCR AutoNormalization
Purpose: To automate library amplification and normalization for FFPE-derived libraries [73].
Materials Required:
- iconPCR system (n6)
- AmpliSeq Library PLUS for Illumina
- Pre-amplified FFPE libraries
- PCR plates and seals
Methodology:
- After initial amplification and cleanup, normalize all samples to approximately 5 ng/μL based on Qubit quantification.
- Prepare PCR reactions according to AmpliSeq specifications with iconPCR master mix.
- Select normalization approach based on sample quality:
- Target Fluorescence: Recommended for most FFPE samples with moderate degradation
- Slope-based: Optimal for highly variable sample quality within a run
- xBaseline: Suitable for uniform sample sets with minimal quality variation
- Run determination cycle with a subset of samples to establish optimal fluorescence thresholds.
- Process full plate with AutoNormalization enabled, allowing the system to automatically adjust cycling parameters for each individual sample.
- For pooling, combine equal volumes of each reaction (for coarse normalization) or use the Pooling by Fluorescence method for improved balance.
Validation: Sequence a test pool and calculate the coefficient of variation (%CV) in read counts across samples. Successful normalization should achieve %CV < 10% [73].
Integrated Workflow for Direct FFPE DNA Processing
The following workflow diagram illustrates the complete integrated process for troubleshooting PCR amplification and library normalization with Direct FFPE DNA samples:
Diagram 1: Integrated workflow for troubleshooting Direct FFPE DNA processing
Research Reagent Solutions
Table 3: Essential Research Reagents for Direct FFPE DNA Protocols
| Reagent/Category | Specific Examples | Function & Application |
|---|---|---|
| FFPE DNA QC Kits | Infinium FFPE QC Kit (Illumina WG-321-1001) [15] | qPCR-based DNA quality assessment using ΔCq metric; determines optimal DNA input |
| Functional DNA Quant | QFI-PCR Assay (Custom TBP target) [69] | Absolute quantification of amplifiable DNA templates; calculates Quantitative Functional Index |
| PCR Enhancers | Betaine (0.5-2.5 M), DMSO (1-10%), BSA (10-100 μg/mL) [72] | Mitigates effects of PCR inhibitors in FFPE samples; improves amplification of degraded DNA |
| Specialized Polymerases | Hot-start DNA polymerases [71] | Reduces non-specific amplification; improves tolerance to common FFPE-derived inhibitors |
| Library Prep System | AmpliSeq for Illumina Direct FFPE DNA [46] [6] | Integrated system for library preparation without DNA purification; optimized for FFPE tissue |
| Normalization Technology | iconPCR AutoNormalization System [73] | Automates library amplification and normalization using real-time fluorescence monitoring |
| RNA Quality Assessment | Bioanalyzer RNA 6000 Nano Kit, Fragment Analyzer Standard Sensitivity RNA Kit [15] | Determines DV200 values for FFPE RNA samples; guides input amount adjustments |
| Nucleic Acid Extraction | QIAGEN AllPrep DNA/RNA FFPE Kit [15] | Simultaneous DNA and RNA extraction from FFPE tissues; recommended for low-input samples |
Successful implementation of the AmpliSeq for Illumina Direct FFPE DNA protocol requires systematic attention to both PCR amplification and library normalization steps. Through rigorous quality assessment using QFI-PCR or Infinium FFPE QC kits, researchers can accurately determine functional DNA quantity before proceeding with library preparation [15] [69]. Optimization of PCR components and cycling parameters specifically for degraded FFPE templates significantly improves library yield and complexity. Most critically, implementing advanced normalization methods such as AutoNormalization or fluorescence-based pooling dramatically reduces representation bias in multiplexed sequencing runs [73].
For laboratories processing diverse FFPE sample sets, establishing pre-analytical quality thresholds (ΔCq ≤ 5 for DNA, DV200 ≥ 55% for RNA) enables evidence-based sample selection and input adjustment [15]. When combined with the specialized reagents and methodologies outlined in this application note, these practices support the generation of high-quality sequencing data from even the most challenging FFPE specimens, ultimately unlocking the vast potential of archival tissue collections for precision medicine research.
Assaying Performance: Validation Data and Comparative Analysis of the Direct FFPE Protocol
The AmpliSeq for Illumina Direct FFPE DNA protocol represents a significant advancement in next-generation sequencing (NGS) for cancer genomics research, enabling direct analysis of formalin-fixed, paraffin-embedded (FFPE) tissues without requiring DNA purification. This technical application note details the rigorous performance validation of this technology, providing researchers and drug development professionals with essential data on its analytical sensitivity, specificity, and reproducibility. The protocol's ability to generate reliable data from challenging FFPE samples—known for yielding partially degraded and chemically modified DNA—makes it particularly valuable for translational research and clinical studies where such archival samples are often the only available resource [28].
Performance characterization is especially critical for FFPE-derived samples due to the inherent nucleic acid damage caused by formalin fixation, including fragmentation, cross-linking, and deamination artifacts that can compromise sequencing accuracy. The data presented herein demonstrate that the AmpliSeq for Illumina technology, with its multiplex PCR-based enrichment and optimized workflow for FFPE samples, maintains robust performance metrics even with these suboptimal starting materials. This validation framework ensures researchers can confidently implement this protocol for comprehensive genomic profiling in personalized medicine approaches [74] [28].
Performance Metrics and Validation Data
Key Performance Metrics for the AmpliSeq FFPE DNA Protocol
Rigorous analytical validation of the AmpliSeq for Illumina Direct FFPE DNA protocol has demonstrated excellent performance across critical parameters essential for reliable variant detection in cancer research. The technology achieves high sensitivity and specificity down to low variant allele frequencies, making it suitable for detecting subclonal populations in heterogeneous tumor samples [74].
Table 1: Comprehensive Performance Metrics for AmpliSeq FFPE DNA Protocol
| Performance Parameter | Specification | Experimental Conditions |
|---|---|---|
| Input Quantity | 1-100 ng DNA | FFPE tissue sections [46] |
| Assay Time | As low as 5 hours | Library preparation only [46] |
| Hands-on Time | 1.5 hours | Manual processing time [46] |
| Sensitivity (SNVs/Indels) | 100% at 2% VAF | 500-1000× coverage [74] |
| Sensitivity (SNVs/Indels) | 96.15% at 1.3% VAF | ~1000× coverage [74] |
| Sensitivity (SNVs/Indels) | 84.62% at 0.6% VAF | ~2000× coverage [74] |
| Specificity | 100% for all variant types | Across SNVs, indels, CNVs, fusions [74] |
| Target Coverage | ≥99% of bases at ≥50× | After UMI analysis [74] |
| Base Quality | ≥94.7% bases ≥Q30 | Quality score threshold [74] |
| Multiplexing Capacity | Up to 96 samples | With unique dual indexes [46] |
The sensitivity and specificity metrics were established using well-characterized reference standards including S800-1 (2% VAF) and S800-2 (0.5% VAF), which contained clinically relevant variants in cancer genes such as EGFR, KRAS, NRAS, and KIT, as well as ALK and ROS1 gene fusions and ERBB2 amplifications [74]. The protocol demonstrated 100% positive percent agreement (PPA) and 100% negative percent agreement (NPA) for all variant types at 2% variant allele frequency (VAF), confirming its robustness for clinical research applications [74].
Reproducibility and Repeatability Data
The reproducibility of the AmpliSeq for Illumina Direct FFPE DNA protocol was systematically evaluated through inter-assay and intra-assay studies. These assessments are critical for establishing the technology's reliability across different experimental conditions and operators, ensuring consistent performance in multi-center studies or longitudinal research projects [74].
Table 2: Reproducibility and Repeatability Assessment
| Assessment Type | Experimental Design | Results |
|---|---|---|
| Inter-Assay Repeatability | Three independent DNA libraries of S800-1 and wild-type standards prepared and sequenced in triplicate on same day, flow cell lane, and system | High concordance with minimal variance in variant calling [74] |
| Inter-Operator Reproducibility | Libraries from same FFPE samples prepared and sequenced on multiple days by different operators | Consistent variant detection across all operators and time points [74] |
| Intra-Run Precision | Multiple samples processed in duplicate or triplicate from same FFPE block (7 submissions processed in duplicate/triplicate, total 33 sequences) | High reproducibility with minimal technical variation [74] |
| Coverage Uniformity | Proportion of target bases covered at >50× depth across multiple runs | 99.95% of bases covered at >50× [74] |
The consistency of the AmpliSeq technology has been further demonstrated in studies beyond human DNA applications. Research on rabies lyssaviruses (RABVs) from FFPE tissues showed successful generation of 33 separate sequences from duplicated and triplicated samples with high reproducibility, confirming the protocol's reliability across different sample types and applications [75].
Experimental Protocols and Methodologies
Sample Preparation and Library Construction
The AmpliSeq for Illumina Direct FFPE DNA protocol features an optimized workflow specifically designed to address the challenges of FFPE-derived genetic material. The methodology eliminates the need for DNA purification, thereby reducing sample loss and handling time while maintaining high-quality sequencing results [19].
The experimental workflow begins with FFPE tissue sections, typically 3-6 sections of 10 µm thickness, placed in microfuge tubes. The protocol utilizes a deparaffinization solution and proteinase K treatment at 60°C for 45 minutes, followed by a heat inactivation step at 80°C for 30 minutes with constant agitation at 300 rpm [75]. This process efficiently reverses formalin-induced crosslinks and recovers amplifiable DNA fragments without requiring traditional nucleic acid extraction methods, significantly reducing hands-on time and potential sample loss [19].
Following sample preparation, the protocol proceeds directly to multiplex PCR amplification using the AmpliSeq for Illumina On-Demand or predefined panels. The AmpliSeq technology employs a highly multiplexed PCR approach with primers designed to generate short amplicons (typically 152-377 bp), which is ideal for fragmented DNA from FFPE samples [46] [75]. This is followed by library construction incorporating unique molecular identifiers (UMIs) and Illumina sequencing adapters. The use of UMIs is particularly valuable for distinguishing true biological variants from artifacts introduced during amplification and sequencing, enhancing the accuracy of variant detection, especially at low allele frequencies [74].
Quality Control and Sequencing Parameters
Maintaining stringent quality control throughout the experimental workflow is essential for generating reliable sequencing data from FFPE samples. The AmpliSeq for Illumina Direct FFPE DNA protocol incorporates multiple QC checkpoints to ensure data integrity and assay performance.
Table 3: Quality Control Parameters and Thresholds
| QC Checkpoint | Parameter | Threshold |
|---|---|---|
| DNA Quality Assessment | DNA amount | ≥50 ng [74] |
| DNA Library Quality Assessment | DNA library amount | ≥600 ng [74] |
| Sequencing Quality Assessment | Average effective sequencing depth | ≥500× (for 2% VAF) / ≥1000× (for 0.5% VAF) [74] |
| Sequencing Quality Assessment | Fraction of target covered with ≥50× | ≥99% [74] |
| Sequencing Quality Assessment | Fraction of base quality ≥Q30 | ≥80% [74] |
For sequencing, the protocol requires data volumes of approximately 5 GB and 17 GB to achieve mean coverages of 500× and 2000×, respectively, after UMI analysis [74]. The achieved mean proportion of bases with quality values ≥Q30 is typically 94.7%, exceeding the minimum threshold and ensuring high-confidence base calling [74]. The correct uniformity is demonstrated by 99.95% of target bases being covered at >50× depth, providing comprehensive coverage of the targeted regions [74].
Essential Research Reagent Solutions
Successful implementation of the AmpliSeq for Illumina Direct FFPE DNA protocol requires several specialized reagents and components designed to work together in an integrated system. These solutions have been optimized specifically for challenging sample types like FFPE tissues.
Table 4: Essential Research Reagent Solutions for AmpliSeq FFPE Protocol
| Reagent Solution | Function | Specifications |
|---|---|---|
| AmpliSeq for Illumina On-Demand Panel | Target enrichment | Custom content from 1-500 genes (24-15,000 amplicons); >5,000 pretested genes available [46] |
| AmpliSeq Library PLUS for Illumina | Library preparation | Includes reagents for preparing 24 or 96 libraries; requires separate panel and indexes [46] |
| AmpliSeq CD Indexes Set A for Illumina | Sample multiplexing | 96 indexes sufficient for labeling 96 samples; enables sample pooling [46] |
| AmpliSeq for Illumina Direct FFPE DNA | FFPE-specific processing | 24 reactions to prepare DNA from unstained, slide-mounted FFPE tissues without deparaffinization or DNA purification [46] |
| AmpliSeq for Illumina Sample ID Panel | Sample tracking | Eight SNP-targeting primer pairs and one gender-discriminating primer pair for 96 reactions; enables sample identification [46] |
The AmpliSeq for Illumina Direct FFPE DNA kit is particularly noteworthy as it enables preparation of DNA from unstained, slide-mounted FFPE tissues without the need for deparaffinization or DNA purification, significantly streamlining the workflow and reducing sample processing time [46]. When combined with the appropriate AmpliSeq panel and Library PLUS reagents, this integrated system provides a complete solution for FFPE-based genomic studies.
Applications in Cancer Genomics Research
The AmpliSeq for Illumina Direct FFPE DNA protocol has demonstrated significant utility in comprehensive genomic profiling for cancer research. In a validation study of a 1021-gene panel performed on over 1300 solid tumor samples encompassing diverse histologies, the technology revealed actionable alterations in more than 50% of cases [74]. The panel detected on-label treatment biomarkers in 12.57% of patients, increasing to 20.15% when immunotherapy markers such as microsatellite instability (MSI) and tumor mutational burden (TMB) were included [74].
The protocol has also proven effective for liquid biopsy applications, demonstrating strong concordance with orthogonal methods and successfully detecting variants in plasma-derived circulating tumor DNA in 70% of evaluable cases [74]. This dual capability for both tissue and liquid biopsies provides researchers with flexible approaches for comprehensive genomic profiling in personalized cancer treatment studies.
Beyond human genomics, the adaptability of the AmpliSeq technology has been demonstrated in viral genomics, where it enabled whole-genome sequencing of rabies lyssaviruses from archived FFPE tissues [75]. This application highlights the technology's versatility across different research domains and sample types, particularly valuable for retrospective studies where only FFPE specimens are available.
The performance metrics detailed in this application note demonstrate that the AmpliSeq for Illumina Direct FFPE DNA protocol provides researchers with a robust, sensitive, and reproducible solution for genomic profiling of challenging FFPE samples. The technology's ability to generate high-quality data from minimal input DNA without purification steps streamlines the workflow and enables comprehensive analysis of valuable archival specimens. With demonstrated sensitivity down to 0.5% VAF for certain variant types, 100% specificity across multiple variant classes, and excellent reproducibility across operators and sequencing runs, this protocol meets the rigorous demands of modern cancer genomics research and drug development programs.
Within genomic research, particularly in studies utilizing Formalin-Fixed Paraffin-Embedded (FFPE) tissue samples, the DNA extraction methodology forms a critical foundation for downstream analytical success. This application note provides a detailed comparative analysis of direct PCR protocols, which circumvent traditional DNA purification, against conventional nucleic acid extraction methods. The content is framed within broader thesis research on the AmpliSeq for Illumina Direct FFPE DNA protocol, which eliminates separate purification steps. For researchers and drug development professionals, the choice between these approaches represents a significant decision point affecting data quality, workflow efficiency, and resource allocation. Evidence from recent studies indicates that direct PCR methods minimize sample loss by reducing tube transfers and purification steps, thereby enhancing the recovery of amplifiable DNA from challenging samples [76]. Conversely, traditional extraction methods, including silica-membrane columns and phenol-chloroform protocols, provide purified DNA that is essential for certain quantitative applications but may introduce substantial DNA loss [77] [78]. This document synthesizes experimental data and standardized protocols to guide methodological selection in clinical and research settings.
Experimental Comparisons & Performance Data
Quantitative Performance Metrics
The following tables summarize key findings from controlled studies comparing direct and traditional methods across various sample types and performance indicators.
Table 1: Comparative Performance of DNA Methods from FFPE Tissues
| Performance Metric | Direct FFPE Protocols | Traditional Extraction Kits | Notes & Experimental Context |
|---|---|---|---|
| Sample Success Rate | 92.8% [79] | >90% (Variable by kit) [80] | TargetPlex FFPE-Direct Kit on NGS panels [79] |
| Variant Detection Sensitivity | 90.5% of variants detected [79] | High concordance (≥86% for SNVs) [80] | Compared to standard NGS workflow [79] |
| Amplifiable Fragment Size | Optimized for shorter amplicons | Up to 400-600 bp with best methods [78] | QIAamp kit enabled 600 bp amplification [78] |
| Hands-on Time | Lower (fewer steps) | Higher (multiple processing steps) [78] | |
| DNA Yield | N/A (No separate elution) | Variable; depends on kit and protocol [77] |
Table 2: Comparison of Direct PCR vs. Extraction for Touch DNA on Various Substrates Data sourced from controlled studies using serially diluted DNA deposited on different surfaces [76].
| Methodology | Average Total Peak Height (TPH) | Average Percentage of Profile Recovered (%P) | Key Substrate Effects |
|---|---|---|---|
| Direct PCR | Consistently Higher | Consistently Higher | Performance varied by substrate (glass, plastic, ceramic, steel) but direct PCR was uniformly superior [76]. |
| QiaAmp DNA Micro Extraction | Significantly Lower | Significantly Lower |
Analysis of Comparative Data
The aggregated data demonstrates a clear trend: direct protocols offer significant efficiency advantages in specific contexts. In the analysis of touch DNA, direct PCR consistently generated profiles with higher total peak heights and a greater percentage of the profile recovered compared to extraction-based methods, irrespective of the substrate tested [76]. Similarly, for NGS of FFPE samples, a direct library preparation kit demonstrated a 92.8% success rate, successfully detecting 90.5% of expected variants while streamlining the workflow [79].
However, traditional extraction methods remain indispensable for applications requiring longer DNA fragments. One study concluded that while extraction methods like the QIAamp kit could enable amplification of fragments up to 600 bp, success was marginal and highly dependent on the extraction method used [78]. Furthermore, comparisons of different FFPE extraction kits (QIAamp, GeneRead, Maxwell) have shown that while all can produce high variant concordance rates with fresh-frozen samples, they can exhibit significant differences in total variant counts and coverage quality, underscoring the need for careful kit selection [80].
Detailed Experimental Protocols
Protocol 1: Direct PCR for Touch DNA Samples
This protocol, adapted for forensic-type samples, allows for DNA amplification directly from a swab without prior purification [76].
- Step 1: Sample Collection. Swab the target substrate (e.g., glass, plastic, fabric) using a sterile cotton swab.
- Step 2: Lysis Preparation. Transfer a portion of the swab or its cutting directly into a PCR tube. Alternatively, incubate the swab in a low-chelex buffer to release DNA into suspension.
- Step 3: Direct PCR Setup. Add PCR components—including a robust hot-start DNA polymerase capable of bypassing inhibitors, primers, and dNTPs—directly to the tube containing the sample.
- Step 4: Thermal Cycling. Perform PCR amplification with an extended initial denaturation step (e.g., 10-15 minutes at 95°C). This prolonged heating is critical for lysing cells and inactivating nucleases without a separate purification step [76].
- Step 5: Product Analysis. Analyze the PCR product using capillary electrophoresis, qPCR, or other appropriate downstream applications.
Protocol 2: Traditional DNA Extraction from FFPE Tissues Using a Silica-Membrane Kit
This is a common and effective method for obtaining purified DNA from FFPE tissues, as referenced in multiple comparative studies [77] [80] [78].
- Step 1: Deparaffinization. Cut 1-3 sections of 5-20 µm thickness from the FFPE block. Transfer to a microcentrifuge tube. Deparaffinize on the slide or in the tube by adding xylene (or a safe substitute), vortexing, and centrifuging. Remove the supernatant. Wash the pellet with descending concentrations of ethanol (e.g., 100%, 96%, 70%) [77].
- Step 2: Proteinase K Digestion. Air-dry the pellet to evaporate residual ethanol. Add 180 µL of digestion buffer and 20 µL of proteinase K (20 mg/mL). Incubate at 55°C for a minimum of 3 hours to a maximum of 72 hours; longer digestion times (e.g., 72 hours) have been shown to significantly increase DNA yield [77].
- Step 3: Lysis and Binding. Follow the kit's specific instructions. Typically, this involves adding a lysis buffer (e.g., AL buffer from QIAamp) and incubating at 70°C for 10-30 minutes. Add ethanol to the lysate to create conditions ideal for DNA binding.
- Step 4: Column Purification. Apply the mixture to a silica-membrane column. Centrifuge to bind the DNA. Wash the column twice with wash buffers (e.g., AW1 and AW2) to remove contaminants, salts, and enzymes.
- Step 5: Elution. Elute the purified DNA in a small volume of low-EDTA TE buffer or nuclease-free water (e.g., 50-100 µL). Incubate the column with the elution buffer for 5 minutes before centrifugation to increase yield.
Workflow Visualization
The following diagram illustrates the fundamental procedural differences between the direct and traditional DNA analysis workflows.
The Scientist's Toolkit: Research Reagent Solutions
Table 3: Essential Reagents and Kits for Direct and Traditional DNA Workflows
| Reagent / Kit Name | Function | Applicable Protocol |
|---|---|---|
| AmpliSeq for Illumina Direct FFPE DNA Kit | Direct library preparation from FFPE samples for NGS, omitting separate extraction. | Direct FFPE NGS |
| TargetPlex FFPE-Direct DNA Library Prep Kit | Direct library preparation from FFPE samples for targeted NGS panels. | Direct FFPE NGS [79] |
| QIAamp DNA FFPE Tissue Kit | Silica-membrane-based purification of DNA from FFPE tissues. | Traditional Extraction [77] [80] |
| Proteinase K (20 mg/mL) | Enzymatic digestion of proteins and disruption of cross-links in FFPE tissues. | Traditional Extraction [77] [78] |
| DNeasy PowerWater Kit | DNA purification from water samples and other low-biomass environments. | Traditional Extraction [81] |
| Robust Hot-Start DNA Polymerase | PCR enzyme resistant to common inhibitors found in crude lysates. | Direct PCR [76] |
| Guanidinium Thiocyanate (GuSCN) Lysis Buffer | Chaotropic salt for cell lysis and DNA binding to silica in in-house methods. | Traditional Extraction [82] |
The choice between direct protocols and traditional purification methods is not a matter of identifying a universally superior option, but rather of selecting the right tool for the specific research question and sample type. Direct protocols excel in efficiency and sensitivity for limited samples. They minimize DNA loss by eliminating multiple tube transfers and purification steps, making them ideal for analyzing low-quantity "touch" DNA samples [76] and for streamlining NGS workflows where input DNA is sufficient without precise quantification [79]. The significant reduction in hands-on time and processing steps also makes these methods highly suitable for high-throughput environments.
Traditional purification methods provide versatility and purity. They are essential for applications requiring analysis of longer DNA fragments, accurate DNA quantification prior to downstream use, or the removal of PCR inhibitors that can be prevalent in complex sample matrices like milk or soil [83] [82]. While all extraction methods can introduce biases in community analysis, traditional protocols allow for a standardized DNA input, which is crucial for comparative metagenomic studies [81].
In conclusion, the AmpliSeq for Illumina Direct FFPE DNA protocol and similar direct methods represent a significant advancement for specific genomic applications, particularly in clinical diagnostics where speed and sample conservation are paramount. However, traditional DNA extraction remains a cornerstone of molecular biology, providing the purity and flexibility required for a broader range of applications. The decision must be informed by a clear understanding of the trade-offs between DNA yield, workflow efficiency, and the specific requirements of the intended analytical platform.
In the realm of targeted next-generation sequencing (NGS) for oncology and genetic disease research, the choice of enrichment methodology is a fundamental decision that directly impacts data quality, workflow efficiency, and project success. Two predominant techniques stand out: amplicon-based sequencing (exemplified by the AmpliSeq for Illumina portfolio, including the Direct FFPE DNA protocol) and hybridization capture-based chemistry [84] [85]. Each method employs a distinct mechanism to enrich for genomic regions of interest (ROIs) from a complex background of whole-genomic DNA, leading to divergent strengths and applications [86]. Within the specific context of analyzing formalin-fixed, paraffin-embedded (FFPE) tissue samples—notorious for their degraded, low-yield, and cross-linked DNA—this choice becomes even more critical. This application note provides a detailed, head-to-head comparison of AmpliSeq and hybrid-capture chemistries, framing the analysis within ongoing research into the streamlined AmpliSeq for Illumina Direct FFPE DNA protocol, which eliminates the need for prior DNA purification. We will dissect the underlying principles, present experimental protocols and performance data, and offer evidence-based guidance for researchers and drug development professionals navigating this key technological decision.
Methodological Principles and Workflow Comparison
The core difference between these methods lies in their initial approach to targeting specific genomic sequences. Understanding these fundamental principles is key to selecting the appropriate methodology.
Amplicon-Based Sequencing (AmpliSeq)
- Core Principle: This method uses multiplex polymerase chain reaction (PCR) with hundreds to thousands of primer pairs to simultaneously amplify specific genomic regions, creating a library of "amplicons" flanked by known adapter sequences [84] [85]. The AmpliSeq for Illumina technology is designed to multiplex up to 24,000 primer pairs in a single reaction, enabling highly efficient enrichment from minimal DNA input [87].
- Workflow: The process is notably streamlined. For the AmpliSeq for Illumina Direct FFPE DNA protocol, unstained FFPE tissue sections are used directly without DNA extraction. The workflow involves targeted amplification via multiplex PCR, followed by partial digestion of primers, ligation of sample-specific barcode adapters, and library purification [46] [19]. The purified library is then ready for sequencing.
Hybridization Capture-Based Sequencing
- Core Principle: This method involves fragmenting genomic DNA and hybridizing it to biotinylated oligonucleotide probes (or "baits") that are complementary to the ROIs. The probe-bound targets are then captured using streptavidin-coated magnetic beads, while non-targeted fragments are washed away [88] [89]. The enriched library is subsequently amplified via PCR.
- Workflow: The hybrid-capture workflow is inherently more complex and time-consuming. It requires high-quality DNA extraction, followed by fragmentation (often via sonication or enzymatic digestion). The fragmented DNA is then ligated to adapters to create a whole-genome library, which serves as the template for solution-based hybridization with the bait library. Post-hybridization, multiple wash steps are required to remove off-target sequences before the final captured library is amplified and purified [88] [85].
Table 1: Core Workflow Characteristics and Requirements
| Feature | Amplicon-Based (AmpliSeq) | Hybridization Capture |
|---|---|---|
| Enrichment Mechanism | Multiplex PCR amplification [84] | Hybridization with biotinylated probes & magnetic bead capture [88] |
| Typical DNA Input | 1-100 ng (as low as 1 ng for FFPE) [46] [87] | 1-250 ng for library prep; 500 ng into capture [84] |
| Hands-on & Assay Time | Lower; ~1.5 hrs hands-on, ~5 hrs total library prep [46] | Higher; more steps and longer turnaround time [86] [89] |
| Key Sample Type | Ideal for FFPE, liquid biopsies, low-input samples [46] [87] | Compatible with FFPE, blood, saliva; requires sufficient input DNA [89] |
Diagram 1: A simplified workflow for AmpliSeq versus Hybrid-Capture methods. AmpliSeq offers a more direct path from sample to library, especially with protocols designed for unpurified FFPE tissue.
Performance and Data Analysis
When selecting an enrichment method, performance metrics are paramount. Each approach exhibits a unique profile of advantages and trade-offs that directly influence data interpretation and reliability.
Key Performance Metrics
A comparative analysis reveals a clear trade-off between on-target efficiency and uniformity of coverage.
- On-target Rate: Amplicon-based methods consistently demonstrate higher on-target rates, as the PCR process is inherently designed to create only the intended products [86]. One study noted that amplicon methods had higher on-target rates compared to hybridization capture [88].
- Uniformity of Coverage: Hybridization capture typically achieves superior uniformity because it captures randomly fragmented DNA, resulting in more even sequencing depth across the target regions. In contrast, amplicon sequencing can exhibit significant coverage variability due to differences in primer amplification efficiency [88].
- Variant Detection Concordance: Despite methodological differences, studies show high concordance for variant calling between the two methods when validated bioinformatics pipelines are used. A 2025 feasibility study on FFPE colorectal cancer samples found approximately 94% concordance for actionable variants in shared genes when comparing an amplicon-based assay (Illumina AmpliSeq v2 Hotspot Panel) to a hybridization capture-based method (TumorSecTM) [90].
Analysis of Different Variant Types
- SNVs and Indels: Both methods are highly effective for detecting single nucleotide variants (SNVs) and small insertions/deletions (indels) [88] [90]. However, amplicon-based methods can be susceptible to false positives or false negatives near primer binding sites due to primer-specific errors [88].
- Complex Variants: Hybridization capture has a distinct advantage for detecting complex variants like gene fusions and copy number variations (CNVs), as it sequences the native genomic fragment context [85] [89]. One study confirmed that hybrid-capture methods demonstrated effective CNV calling when evaluated against a SNP array [88]. Amplicon methods can struggle with these unless specially designed (e.g., using anchored multiplex PCR) [85].
- Ability to Discover Novel Variants: The hybrid-capture approach is better suited for discovering novel variants, including structural variants and mutations in non-hotspot regions, due to its more comprehensive and unbiased profiling of the entire ROI [89].
Table 2: Performance and Application Comparison
| Parameter | Amplicon-Based (AmpliSeq) | Hybridization Capture |
|---|---|---|
| On-target Rate | Higher [88] [86] | Lower |
| Coverage Uniformity | Lower [88] | Higher [88] [86] |
| Variant Concordance | ~94% vs. Capture for SNVs/Indels [90] | ~94% vs. Amplicon for SNVs/Indels [90] |
| Best for Variant Types | Known SNVs/Indels, Hotspots [86] [89] | CNVs, Fusions, Novel/Complex Variants [85] [89] |
| Ideal Panel Size | Smaller content, typically < 50 genes [89] | Larger content (exomes, >50 genes) [89] |
Experimental Protocols for FFPE Tissue
This section outlines detailed methodologies for applying both enrichment techniques to FFPE tissue samples, with a special emphasis on the purification-free AmpliSeq protocol.
AmpliSeq for Illumina Direct FFPE DNA Protocol
This protocol is designed to minimize hands-on time and mitigate challenges associated with FFPE-derived DNA.
- Step 1: Sample Preparation. Using a microtome, cut one or two 10 μm sections from an FFPE tissue block and place them directly into a nuclease-free PCR plate or tube. No deparaffinization or DNA purification is required [19].
- Step 2: Lysis and Digestion. Add the provided Lysis Solution and Proteinase K to the sample. Incubate at a defined temperature (e.g., 70°C) to reverse formalin cross-links and digest the tissue, followed by a higher-temperature step to inactivate the enzyme.
- Step 3: Multiplex PCR. Directly use a portion of the lysate as the template for the first-stage multiplex PCR. The AmpliSeq for Illumina panel, containing primer pairs for the targeted genes, is added. The PCR is run for a defined number of cycles to amplify the ROIs.
- Step 4: Library Construction. Following PCR, FuPa Reagent is added to partially digest the primer sequences and prepare the amplicon ends for adapter ligation. Subsequently, Illumina-specific barcoded adapter indexes are ligated to the amplicons to create the final sequencing library.
- Step 5: Library Purification and Normalization. The library is purified using magnetic beads to remove enzymes, salts, and unused adapters. The purified libraries are then quantified and normalized before pooling for sequencing on an Illumina system [46] [19].
Hybrid-Capture Protocol for FFPE DNA
This protocol requires high-quality, purified DNA as a starting point.
- Step 1: DNA Extraction and QC. Extract DNA from FFPE tissue sections using a dedicated FFPE DNA purification kit. Quantify the DNA using a fluorescence-based assay (e.g., Qubit) and critically assess its quality and fragment size using an instrument like the TapeStation or Bioanalyzer. DNA with a peak size below 200 bp is often not recommended for hybrid-capture workflows due to poor capture efficiency [90].
- Step 2: Library Preparation. Fragment the purified genomic DNA to a target size of 150-300 bp, typically via acoustic shearing (Covaris) or enzymatic fragmentation. Repair the fragment ends, add A-tails, and ligate platform-specific adapters containing sample indexes to create the "whole-genome" sequencing library [88] [90].
- Step 3: Hybridization and Capture. Denature the library and hybridize it with the biotinylated probe library for the target regions (e.g., whole exome or a specific gene panel) for a prolonged period (16-24 hours). After hybridization, add streptavidin-coated magnetic beads to capture the probe-bound targets. Perform a series of stringent washes to remove non-specifically bound or off-target fragments [88] [85].
- Step 4: Post-Capture Amplification and QC. Perform a final PCR amplification (e.g., 10-14 cycles) to enrich the captured library. Purify the final product and quality-control it using a TapeStation or similar method before sequencing [88].
The Scientist's Toolkit: Essential Reagents and Materials
Successful implementation of these NGS workflows requires a suite of specialized reagents and instruments.
Table 3: Key Research Reagent Solutions for Targeted NGS
| Item | Function | Example Products |
|---|---|---|
| Targeted Panel | Contains primers or probes for specific genomic regions. | AmpliSeq for Illumina On-Demand Panel [46], SeqCap EZ Choice Library [88] |
| Library Prep Kit | Reagents for DNA fragmentation, adapter ligation, and amplification. | AmpliSeq Library PLUS for Illumina [46], KAPA HyperPlus Kit [90] |
| Index Adapters | Barcoded sequences for multiplexing samples. | AmpliSeq CD Indexes [46], IDT for Illumina UD Indexes |
| FFPE-Optimized Kits | Specialized reagents for challenging FFPE samples. | AmpliSeq for Illumina Direct FFPE DNA Kit [19] |
| Capture Beads | Magnetic beads for post-hybridization purification. | Streptavidin-coated magnetic beads [85] |
| Nucleic Acid Quantitation | Accurate measurement of DNA concentration and quality. | Qubit dsDNA HS Assay, Agilent TapeStation/Bioanalyzer [88] [90] |
Discussion and Strategic Implementation
The choice between AmpliSeq and hybrid-capture chemistry is not a matter of one being universally superior, but rather of matching the technology to the specific research question, sample type, and operational constraints.
For research focused on a defined set of genes—such as hotspot mutations in cancer—with compelling needs for speed, low DNA input, and cost-effectiveness, the AmpliSeq for Illumina Direct FFPE DNA protocol presents a powerful solution. Its streamlined, purification-free workflow is a significant advantage for high-throughput screening of precious FFPE archives, enabling rapid turnaround from tissue to sequence data [46] [19]. The high concordance rates for SNVs and indels make it highly reliable for validated biomarker panels [90].
Conversely, for discovery-oriented applications requiring a comprehensive view of genetic alterations, including CNVs, fusions, and novel variants across a large number of genes or the entire exome, hybridization capture remains the gold standard [85] [89]. Its superior uniformity and ability to profile complex variant types justify the additional input requirements, hands-on time, and cost for these applications.
Diagram 2: A decision pathway to guide the selection of the most suitable target enrichment method based on key project requirements.
For drug development professionals, this translates into strategic workflow design. AmpliSeq is ideal for pharmacogenomics studies, clinical trial stratification based on known biomarkers, and large-scale retrospective studies using FFPE tissue biobanks. Hybrid-capture is indispensable for comprehensive genomic profiling in early-stage discovery, biomarker identification, and understanding complex mechanisms of drug resistance. As the field advances, the integration of robust, population-specific bioinformatics pipelines—like the TumorSecTM pipeline validated in Latin American populations—will be just as critical as the wet-lab methodology in ensuring accurate and actionable results for personalized cancer treatment [90].
Molecular profiling of bone metastasis specimens is essential for personalized cancer therapy, but the required decalcification process often compromises nucleic acid integrity, challenging reliable genetic analysis. This case study evaluates the performance of EDTA-based decalcification followed by targeted next-generation sequencing (NGS) using AmpliSeq for Illumina technology. Within the broader research context of the AmpliSeq for Illumina Direct FFPE DNA protocol without purification, this application note demonstrates that EDTA-decalcified bone specimens can yield mutation detection results comparable to non-decalcified tissues, enabling broader inclusion of precious bone metastasis samples in clinical testing and research [60].
Experimental Design and Sample Characteristics
This study analyzed 752 formalin-fixed paraffin-embedded (FFPE) samples, including 31 EDTA-decalcified bone specimens and 721 non-decalcified controls. The EDTA-decalcified cohort primarily consisted of metastatic lung adenocarcinomas (22/31, 71%), with other tumor types including breast carcinoma, melanoma, and gastrointestinal stromal tumor (GIST) [60]. Sample characteristics are summarized in Table 1.
Table 1: Characteristics of EDTA-Decalcified Study Cohort
| Characteristic | Value (n=31) |
|---|---|
| Tumor Types | |
| Lung Adenocarcinoma | 22 (71.0%) |
| Breast Carcinoma | 4 (12.9%) |
| Melanoma | 2 (6.5%) |
| Other (Mastocytosis, CUP, GIST) | 3 (9.6%) |
| Decalcification Duration | |
| Average Time | 2.4 days |
| Range | 1-5 days |
| Specimen Type | Bone specimens (30), heavily calcified GIST (1) |
All samples underwent EDTA decalcification using Osteosoft (Merck, Germany) with duration adapted to specimen size, ranging from short durations to overnight cycles of approximately 6 hours each [91] [60]. This gentle chelating approach preserves DNA integrity far better than harsh acid decalcifiers [91].
Methodology
DNA Extraction and Quality Control
Genomic DNA was extracted from FFPE tissue sections using the Qiagen AllPrep DNA/RNA FFPE Kit (QIAGEN GmbH, Hilden, Germany). DNA quantity was assessed using both NanoDrop ND-2000 spectrophotometer and Qubit Quantification Assay (Thermo Fisher Scientific) to obtain comprehensive quality metrics [60]. This dual quantification approach is critical for accurate DNA assessment, as demonstrated by optimization studies showing that protocol modifications can increase DNA yields by 82% and significantly improve DNA Integrity Numbers [92].
Library Preparation and Sequencing
Libraries were prepared using the Ion Torrent Ampliseq 2.0 kit (Thermofisher, Carlsbad, CA, USA) with a customized 30-gene NGS panel targeting common clinically relevant mutations, including single-nucleotide variants (SNVs) and indels [60]. Template preparation and sequencing were performed on the Ion Torrent platform, with sequencing considered optimal if ≥95% of target regions achieved ≥250X coverage depth [60]. The AmpliSeq for Illumina technology is particularly suited for degraded samples like FFPE tissues, requiring only 1-100 ng DNA input with minimal hands-on time [46].
Data Analysis
Statistical comparisons between EDTA-decalcified and non-decalcified groups were performed using Pearson's Chi-squared test for categorical variables and the Wilcoxon rank-sum test for continuous variables [60]. A key strength of this analytical approach was the use of multiple quality metrics to comprehensively assess DNA suitability for NGS applications.
Diagram 1: Experimental workflow for mutation detection in EDTA-decalcified bone specimens
Results and Data Analysis
DNA Quality and Quantity Metrics
Comparative analysis revealed that EDTA-decalcified specimens produced DNA quality and quantity metrics largely comparable to non-decalcified controls, with some expected variations. While NanoDrop measurements showed statistically significant differences, the more accurate Qubit measurements demonstrated no significant difference in DNA concentration between groups [60]. Key quantitative findings are summarized in Table 2.
Table 2: DNA Quality and Quantity Comparison Between EDTA-Decalcified and Non-Decalcified Specimens
| Parameter | EDTA-Decalcified (n=31) | Non-Decalcified (n=721) | p-value |
|---|---|---|---|
| Suboptimal Sequencing | 9.7% (3/31) | 9.0% (65/721) | 0.9 |
| DNA Concentration (Qubit) | 31.60 ng/µL (IQR: 16.09-60.50) | 37.00 ng/µL (IQR: 18.14-66.80) | 0.4 |
| DNA Concentration (NanoDrop) | 116.80 ng/µL (IQR: 63.70-178.05) | 180.40 ng/µL (IQR: 88.30-343.60) | 0.006 |
| NanoDrop 260/280 Ratio | 1.89 (IQR: 1.86-1.93) | 1.90 (IQR: 1.87-1.92) | 0.8 |
| NanoDrop 260/230 Ratio | 1.86 (IQR: 1.53-2.06) | 2.02 (IQR: 1.72-2.21) | 0.002 |
The 260/280 ratios near 1.9 indicate pure nucleic acid preparations in both groups, while the slightly lower 260/230 ratios in EDTA-decalcified samples suggest some carryover of EDTA or other salts that absorb at 230 nm [60]. Despite this, the lower 260/230 ratio did not impact library preparation success or necessitate additional sample repetition.
Sequencing Performance and Mutation Detection
The suboptimal sequencing rate of 9.7% in EDTA-decalcified specimens was not significantly different from the 9.0% rate in non-decalcified controls (p=0.9) [60]. None of the samples in either group resulted in complete sequencing failure, demonstrating the robustness of this approach. The mutation profile detected in decalcified samples aligned with expected patterns for respective tumor types, validating the analytical sensitivity of the method [60].
Diagram 2: Sequencing performance and outcomes for EDTA-decalcified specimens
Comparative Analysis of Decalcification Methods
This study's findings align with previous research comparing decalcification methods. A 2020 study evaluating lung carcinoma bone metastases found that 41.2% of samples (14/34) were unsuitable for NGS analysis following decalcification, primarily when using formic acid-based methods [93]. Another comprehensive study demonstrated that hydrochloric acid and long-term formic acid decalcification consistently produced false-negative results in immunohistochemistry and molecular analyses, while EDTA and short-term formic acid decalcification (<5 cycles of 6 hours each) preserved antigenicity and enabled reliable detection of gene mutations, amplifications, and fusion transcripts [91].
The Scientist's Toolkit: Essential Research Reagents
Table 3: Essential Research Reagents for EDTA-Decalcified FFPE Tissue Analysis
| Reagent/Kit | Manufacturer | Primary Function |
|---|---|---|
| Osteosoft EDTA | Merck, Germany | Gentle decalcification of bone tissue preserving nucleic acids |
| AllPrep DNA/RNA FFPE Kit | QIAGEN GmbH, Hilden, Germany | Simultaneous extraction of DNA and RNA from FFPE tissues |
| AmpliSeq for Illumina Direct FFPE DNA | Illumina | Library preparation directly from FFPE tissues without purification |
| Ion Torrent Ampliseq 2.0 Kit | Thermo Fisher Scientific | Targeted library preparation for sequencing |
| Custom 30-Gene Panel | Laboratory-developed | Targeted mutation detection for common cancer-associated genes |
| NanoDrop Spectrophotometer | Thermo Fisher Scientific | Nucleic acid quantification and purity assessment (260/280, 260/230) |
| Qubit Quantification Assay | Thermo Fisher Scientific | Highly accurate DNA quantification using fluorescent dyes |
This case study demonstrates that EDTA-decalcified FFPE bone tissues produce NGS results comparable to non-decalcified specimens when processed using optimized protocols. The similar rates of suboptimal sequencing between groups (9.7% vs. 9.0%) and successful detection of expected mutation profiles support EDTA decalcification as a suitable method for molecular diagnostics [60]. These findings enable broader inclusion of bone metastasis specimens in clinical testing, particularly valuable when bone lesions are the only accessible tumor tissue. Implementation of the AmpliSeq for Illumina Direct FFPE DNA protocol without purification represents a significant advancement for molecular pathology, expanding diagnostic capabilities while preserving precious limited specimens.
For clinical and research genomics, establishing the accuracy and reliability of new next-generation sequencing (NGS) methods is paramount. Concordance studies serve as a critical component of assay validation, ensuring that variant calls from a new platform are consistent with those from established orthogonal methods or well-characterized reference benchmarks [94] [95]. With the increasing use of challenging sample types like formalin-fixed, paraffin-embedded (FFPE) tissues, which often yield degraded and low-quality DNA, robust benchmarking is essential to confirm that simplified preparation methods, such as the AmpliSeq for Illumina Direct FFPE DNA protocol, do not compromise data integrity. This application note details experimental protocols and presents benchmarked data for conducting such concordance studies, providing a framework for validating targeted sequencing workflows against standard-of-care genomic approaches.
Experimental Protocols for Concordance Assessment
Benchmark Sample Preparation and Sequencing
Utilizing well-characterized reference samples is a cornerstone of rigorous concordance analysis. The following protocol leverages the National Institute of Standards and Technology (NIST) Genome in a Bottle (GIAB) benchmark to establish baseline performance.
- Reference Materials: Acquire NIST GIAB benchmark cell lines (e.g., NA12878/HG001) from reputable sources like the Coriell Institute for Medical Research. These samples have extensively validated, high-confidence variant calls available for comparison [94] [96].
- DNA Extraction and QC: Extract genomic DNA using the standard silica-column-based methods (e.g., QIAamp DNA Mini Kit) for the reference samples. For FFPE samples, use the AmpliSeq for Illumina Direct FFPE DNA kit, which allows for library construction from slide-mounted tissues without prior deparaffinization or DNA purification, significantly streamlining the workflow [97] [19]. Quantify DNA using a fluorometer (e.g., Qubit).
- Library Preparation and Sequencing: For targeted sequencing, employ the AmpliSeq for Illumina On-Demand or a custom panel following the manufacturer's instructions [46].
- Use 1-100 ng of input DNA. The library preparation hands-on time is approximately 1.5 hours, with a total assay time of about 5-7.5 hours.
- Sequencing: Sequence the prepared libraries on an appropriate Illumina platform (e.g., MiSeq, NextSeq 550, or NovaSeq 6000 System) using paired-end 150-cycle chemistry to ensure sufficient coverage and read length for accurate variant calling [96] [95].
Bioinformatic Processing and Variant Calling
A robust bioinformatics pipeline is essential for accurate variant identification. The following steps outline a standard workflow:
- Primary and Secondary Analysis: Demultiplex sequencing data using Illumina's bcl2fastq or BCLConvert software. Perform adapter trimming, align reads to the reference genome (e.g., GRCh37/hg19 or GRCh38), and mark duplicate reads using aligners like BWA or integrated solutions like the DRAGEN platform [96] [98].
- Variant Calling: Call single nucleotide variants (SNVs) and small insertions/deletions (indels) using validated variant callers. For a comprehensive approach, implement a combination of multiple callers to maximize sensitivity and specificity [94]. Apply minimum quality filters, such as a coverage depth of 8-20x and an allele frequency threshold of 20% for heterozygous calls [96].
- Variant Annotation and Comparison: Annotate called variants using standard databases and intersect the resulting VCF file with the high-confidence NIST benchmark variant set for the corresponding sample. Use tools like BEDTools to restrict analysis to clinically relevant exonic regions [94]. Compare VCF files at the chromosome, position, reference, and alternate allele levels to identify exact matches, false positives, and false negatives [94].
Key Performance Metrics and Benchmarking Data
The tables below summarize key performance metrics from published concordance studies, illustrating the high standard achievable with validated NGS workflows.
Table 1: SNV and Indel Concordance Metrics from Orthogonal Studies
| Study Focus / Platform | Sample Type / Benchmark | Analytical Sensitivity | Analytical Specificity | Key Concordance Finding |
|---|---|---|---|---|
| Long-Read Sequencing Pipeline [94] | NIST GIAB NA12878 (exonic regions) | 98.87% | >99.99% | Detection of 167/168 (99.4%) clinically relevant variants in 72 clinical samples. |
| NovaSeq 6000 RUO vs. CE-IVD [95] | 96 Clinical WES Samples | 100% (for SNVs) | 100% | Full agreement for clinically relevant SNVs between automated RUO and diagnostic platforms. |
| NovaSeq X Plus vs. Ultima UG 100 [98] | NIST v4.2.1 HG002 (all regions) | N/A | N/A | 6x fewer SNV errors and 22x fewer indel errors vs. UG 100 platform against the full benchmark. |
Table 2: Structural and Copy Number Variant Concordance
| Variant Type | Study Platform | Concordance Metric | Notes |
|---|---|---|---|
| CNVs > 150 kb | NovaSeq 6000 WES [95] | 79% Positive Percent Agreement | Performance improves with variant size. |
| CNVs > 900 kb | NovaSeq 6000 WES [95] | 91.7% Positive Percent Agreement | Highlights the importance of size thresholds for reliable CNV detection. |
| Overall SVs | NovaSeq X Plus [98] | 88% Sensitivity (vs. NIST T2T benchmark) | Demonstrates capability for comprehensive structural variant detection. |
The Scientist's Toolkit: Essential Research Reagent Solutions
The following reagents are critical for executing the concordance studies and protocols described herein.
Table 3: Key Reagents for AmpliSeq-based Concordance Studies
| Research Reagent Solution | Function in Workflow | Specifications |
|---|---|---|
| AmpliSeq for Illumina Direct FFPE DNA [97] [19] | Enables direct library construction from FFPE tissue sections. | 24 reactions per kit. Bypasses deparaffinization and purification. |
| AmpliSeq for Illumina On-Demand Panel [46] | Provides a customizable, pretested gene panel for targeted sequencing. | Choice of 1-500 genes (up to 15,000 amplicons). 24 or 96 reactions. |
| AmpliSeq Library PLUS for Illumina [47] [46] | Contains master mix and enzymes for PCR-based library construction. | Available in 24, 96, and 384 reactions. |
| AmpliSeq CD Indexes for Illumina [47] [46] | Allows for multiplexing of samples by attaching unique barcode sequences. | Available in sets of 24 or 96 indexes. |
| NIST GIAB Reference Materials [94] [96] | Provides a gold-standard benchmark for validating variant calls. | DNA from cell lines (e.g., NA12878) with high-confidence variant sets. |
Workflow and Data Analysis Diagrams
The following diagram illustrates the logical flow and decision points in a comprehensive concordance study, from sample preparation to final analysis.
Systematic concordance studies are fundamental for verifying the performance of genomic assays, especially when implementing streamlined protocols like the AmpliSeq for Illumina Direct FFPE DNA method. The data and protocols outlined herein demonstrate that modern NGS workflows, when properly validated against orthogonal methods and reference standards, can achieve exceedingly high concordance rates for SNVs, indels, and larger structural variants. By adhering to these detailed experimental and analytical guidelines, researchers and clinical laboratory professionals can confidently generate reliable, high-quality genomic data from even the most challenging FFPE samples, thereby accelerating drug development and enhancing diagnostic precision.
Conclusion
The AmpliSeq for Illumina Direct FFPE DNA protocol represents a significant advancement in NGS for biomedical research, effectively overcoming major hurdles associated with FFPE and decalcified bone samples. By eliminating the deparaffinization and purification steps, it streamlines the workflow, reduces hands-on time, and minimizes sample loss. As demonstrated through rigorous validation, this method produces high-quality, reliable sequencing data compatible with a wide range of targeted panels, from cancer genomics to immunology. Its robustness, especially when paired with appropriate QC measures, makes it an indispensable tool for unlocking the vast potential of archival clinical samples. Future directions will likely focus on expanding panel content, further automating the workflow, and integrating this powerful approach into larger multi-omics studies in clinical and translational research settings.
References
- 1. Overcoming FFPE Challenges: The Power of High-Efficiency ... [https://www.yeasenbio.com/blogs/ngs/overcoming-ffpe-challenges-the-power-of-high-efficiency-dna-repair-reagents]
- 2. NGS from FFPE samples [https://www.qiagen.com/us/qdm/qfdk/ngs-from-ffpe-samples/]
- 3. A critical spotlight on the paradigms of FFPE-DNA ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC10415133/]
- 4. Comparison of Clinical Targeted Next-Generation ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC4912568/]
- 5. Estimation of age-related DNA degradation from formalin ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC5609301/]
- 6. AmpliSeq for Illumina Custom DNA Panel [https://www.illumina.com/products/by-type/sequencing-kits/library-prep-kits/ampliseq-custom-dna-panel.html]
- 7. Ion AmpliSeq Custom Targeted NGS Testing Panels [https://www.thermofisher.com/us/en/home/life-science/sequencing/next-generation-sequencing/ion-torrent-next-generation-sequencing-workflow/ion-torrent-next-generation-sequencing-select-targets/ampliseq-target-selection.html]
- 8. Comparative analysis of library preparation approaches for ... [https://www.nature.com/articles/s41598-025-12992-7]
- 9. An efficient procedure for the recovery of DNA ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC9351614/]
- 10. DNA Extraction from FFPE Tissues for NextGen Sequencing [https://bitesizebio.com/36731/dna-extraction-from-ffpe-tissues-for-nextgen-sequencing/]
- 11. Ion AmpliSeq™ Direct FFPE DNA Kit 8 Preps | Buy Online [https://www.thermofisher.com/order/catalog/product/A31133]
- 12. ReliaPrep™ FFPE gDNA Miniprep System [https://www.promega.com/products/nucleic-acid-extraction/genomic-dna/reliaprep-ffpe-gdna-miniprep-system/]
- 13. Phire & Phusion Direct PCR Master Mixes [https://www.thermofisher.com/us/en/home/brands/thermo-scientific/molecular-biology/thermo-scientific-pcr/direct-pcr-master-mixes-thermo-scientific.html]
- 14. AmpliSeq for Illumina Sequencing Solution [https://support1.dev-web.illumina.com.cn/content/illumina-marketing/apac/en/products/by-brand/ampliseq.html]
- 15. Recommended quality control of FFPE samples for Illumina ... [https://knowledge.illumina.com/library-preparation/general/library-preparation-general-reference_material-list/000001941]
- 16. AmpliSeq for Illumina Sequencing Solution [https://www.illumina.com/products/by-brand/ampliseq.html]
- 17. AmpliSeq Library PLUS for Illumina Compatible Products [https://support.illumina.com/sequencing/sequencing_kits/ampliseq-library-plus-for-illumina/compatibility.html]
- 18. AmpliSeq for Illumina Library Prep, Indexes, and Accessories [https://www.illumina.com/products/by-type/sequencing-kits/library-prep-kits/ampliseq-library-plus-adapters-accessories.html]
- 19. AmpliSeq for Illumina Direct FFPE DNA Kit Reference Guide [https://support.illumina.com/downloads/ampliseq-direct-FFPE-DNA-kit-for-illumina-reference-guide-1000000056164.html]
- 20. Ion AmpliSeq NGS Panels for Targeted Sequencing [https://www.thermofisher.com/us/en/home/products-and-services/promotions/life-science/ampliseq-ngs-panels-targeted-sequencing.html]
- 21. Complete Guide to Ion Ampliseq Technology [https://www.thermofisher.com/blog/behindthebench/complete-guide-to-ion-ampliseq-technology-how-does-ion-ampliseq-technology-work/]
- 22. Design custom NGS panels with Ion AmpliSeq Designer [https://www.ampliseq.com/]
- 23. AmpliSeq™ for Illumina® Direct FFPE DNA [https://www.govsci.com/product-detail/Illumina-----Inc/20023378/EA/?srsltid=AfmBOoqrV87qmVm-sCSXMYqOaD8LxoLm8Xh3NmfY8JKFd4FZxIwjX7gs]
- 24. FFPE tissue preparation and FISH protocol [https://www.ogt.com/resources/fish-resources-and-support/introduction-to-fish/fish-procedures/ffpe-tissue-preparation-and-fish-protocol/]
- 25. DNA extraction from FFPE tissue samples – a comparison ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC6500389/]
- 26. Systematic comparison of two whole-genome amplification ... [https://www.nature.com/articles/s41598-017-04419-9]
- 27. FFPE Tissue Samples for Genomics Study and Analysis ... [https://www.precedenceresearch.com/ffpe-tissue-samples-for-genomics-study-and-analysis-market]
- 28. FFPE Sample Analysis with Sequencing and Arrays [https://www.illumina.com/science/education/ffpe-sample-analysis.html]
- 29. Illumina DNA Prep | Flexibility for many genome ... [https://www.illumina.com/products/by-type/sequencing-kits/library-prep-kits/illumina-dna-prep.html]
- 30. Optimization of methylation capture sequencing workflow ... [https://www.sciencedirect.com/science/article/pii/S136883752500291X]
- 31. Illumina Innovation Roadmap [https://www.illumina.com/science/genomics-research/innovation-roadmap.html]
- 32. Ion AmpliSeq™ Direct FFPE DNA Kit [http://www.abm.com.ge/en/68-Reagents%20and%20Consumables/223-Ion%20AmpliSeq%E2%84%A2%20Direct%20FFPE%20DNA%20Kit]
- 33. AmpliSeq for Illumina Ready-to-Use Panels [https://www.illumina.com/products/by-brand/ampliseq/ready-to-use-panels.html]
- 34. Release Notes [https://www.ampliseq.com/displayChangeLog.action]
- 35. Ion AmpliSeq™ Mouse TCR Beta SR Assay, DNA [https://www.thermofisher.com/order/catalog/product/A45488]
- 36. Sequencing Platform Comparison Tool [https://emea.illumina.com/systems/sequencing-platforms/comparison-tool_msm_moved_msm_moved.html]
- 37. MiSeq Sequencing System specifications [https://www.illumina.com/systems/sequencing-platforms/miseq/specifications.html]
- 38. NextSeq 1000 & 2000 System Specifications [https://www.illumina.com/systems/sequencing-platforms/nextseq-1000-2000/specifications.html]
- 39. iSeq 100 Sequencing System specifications [https://www.illumina.com/systems/sequencing-platforms/iseq/specifications.html]
- 40. iSeq 100 Sequencing System [https://www.illumina.com/systems/sequencing-platforms/iseq.html]
- 41. MiSeq i100 Series Specifications | Run time, output, and ... [https://www.illumina.com/systems/sequencing-platforms/miseq-i100/specifications.html]
- 42. NextSeq 550 Sequencing System specifications [https://www.illumina.com/systems/sequencing-platforms/nextseq/specifications.html]
- 43. Comparison of iSeq and MiSeq as the two platforms for ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC9628524/]
- 44. Bioinformatics and DNA -extraction strategies to reliably detect genetic... [https://pubmed.ncbi.nlm.nih.gov/31477010/]
- 45. DEEPOMICS FFPE , a deep neural network model, identifies DNA ... [https://www.nature.com/articles/s41598-024-53167-0?error=cookies_not_supported&code=5f65c442-fcd9-48f0-9c12-55f495d1a4a1]
- 46. AmpliSeq for Illumina On-Demand [https://www.illumina.com/products/by-type/sequencing-kits/library-prep-kits/ampliseq-on-demand-panel.html]
- 47. AmpliSeq for Illumina TCR beta-SR Panel | FFPE-compatible [https://www.illumina.com/products/by-type/sequencing-kits/library-prep-kits/ampliseq-tcr-beta-sr-panel.html]
- 48. improving structural variant calling in FFPE samples - PMC [https://pmc.ncbi.nlm.nih.gov/articles/PMC8458033/]
- 49. Best practices for evaluating single nucleotide variant ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC4493402/]
- 50. Comprehensive genome analysis and variant detection at ... [https://www.nature.com/articles/s41587-024-02382-1]
- 51. Illumina FFPE DNA Prep with Exome 2.5 Enrichment [https://www.illumina.com/products/by-type/sequencing-kits/library-prep-kits/ffpe-dna-prep-exome-enrichment.html]
- 52. Infinium FFPE QC and DNA Restoration Kits [https://www.illumina.com/products/by-type/molecular-biology-reagents/infinium-ffpe-qc-dna-restoration.html]
- 53. Quality control recommendations for RNASeq using FFPE ... [https://www.rna-seqblog.com/quality-control-recommendations-for-rnaseq-using-ffpe-samples/]
- 54. Use and Misuse of Cq in qPCR Data Analysis and Reporting [https://pmc.ncbi.nlm.nih.gov/articles/PMC8229287/]
- 55. qPCR Double Delta Ct Analysis in 4 Easy Steps [https://bitesizebio.com/24894/4-easy-steps-to-analyze-your-qpcr-data-using-double-delta-ct-analysis/]
- 56. Overcoming challenges in FFPE DNA library prep [https://www.neb.com/en-us/nebinspired-blog/overcoming-challenges-in-ffpe-dna-library-prep?srsltid=AfmBOoqSr1fx-NYEn3y1014wOTMyUv_GJhNi_-8xxIitrRabhLKIARYN]
- 57. Impact of Reducing DNA Input on Next-Generation ... [https://www.sciencedirect.com/science/article/pii/S1525157820300428]
- 58. Integration of next-generation sequencing in clinical ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC5243883/]
- 59. DNA Library Preparation [https://www.illumina.com/techniques/sequencing/ngs-library-prep/dna.html]
- 60. Decalcified, Formalin-Fixed Paraffin-Embedded (FFPE) ... [https://www.mdpi.com/2673-5261/6/3/21]
- 61. Qualitative comparison of decalcifiers for mouse bone ... [https://www.nature.com/articles/s41598-024-84330-2]
- 62. Hypertonic saline- and detergent-accelerated EDTA-based ... [https://www.nature.com/articles/s41598-024-61459-8]
- 63. Comparison between Conventional Decalcification and a ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC7422918/]
- 64. Identification of Optimal Decalcification Method and Tissue ... [https://www.mdpi.com/2304-6767/13/11/538]
- 65. Forensic DNA Recovery from FFPE Tissue Using the ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12469798/]
- 66. A nanoscale quality control framework for assessing FFPE ... [https://pubs.rsc.org/en/content/articlehtml/2025/nh/d5nh00176e]
- 67. Assessing DNA Degradation through Differential ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC11120943/]
- 68. Input DNA/RNA QC [https://nanoporetech.com/document/input-dna-rna-qc]
- 69. Functional DNA quantification guides accurate next ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC3978876/]
- 70. How to Troubleshoot Sequencing Preparation Errors (NGS ... [https://www.cd-genomics.com/resource-sequencing-preparation-troubleshooting.html]
- 71. PCR Troubleshooting Guide | Thermo Fisher Scientific - US [https://www.thermofisher.com/us/en/home/life-science/cloning/cloning-learning-center/invitrogen-school-of-molecular-biology/pcr-education/pcr-reagents-enzymes/pcr-troubleshooting.html]
- 72. Polymerase Chain Reaction: Basic Protocol Plus ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC4846334/]
- 73. Higher quality and larger scale high throughput library prep [https://www.news-medical.net/whitepaper/20251022/Higher-quality-and-larger-scale-high-throughput-library-prep.aspx]
- 74. Comprehensive Evaluation of a 1021-Gene Panel in FFPE ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12249698/]
- 75. Ampliseq for Illumina Technology Enables Detailed Molecular ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC9610640/]
- 76. A comparison between direct PCR and extraction to ... [https://www.sciencedirect.com/science/article/abs/pii/S1872497311001803]
- 77. Comparison of Methods for the Extraction of DNA from ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC3970103/]
- 78. Comparative analysis of four methods to extract DNA from ... [https://bmcresnotes.biomedcentral.com/articles/10.1186/1756-0500-3-239]
- 79. TargetPlex FFPE-Direct DNA Library Preparation Kit for ... [https://pubmed.ncbi.nlm.nih.gov/33766954/]
- 80. Performance comparison of three DNA extraction kits on ... [https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0195471]
- 81. Evaluation of DNA extraction methods and direct PCR in ... [https://www.frontiersin.org/journals/microbiology/articles/10.3389/fmicb.2023.1151907/full]
- 82. Comparison of DNA Extraction Methods for the Direct ... [https://www.mdpi.com/2073-4441/14/22/3736]
- 83. Comparative analysis of the effects of different purification ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC11080921/]
- 84. Amplicon Sequencing vs. Hybridization Capture [https://www.cd-genomics.com/diseasepanel/amplicon-sequencing-vs-hybridization-capture-the-comparison-of-target-enrichment-methods-for-disease-panel.html]
- 85. Target Enrichment Approaches for Next-Generation ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC9318977/]
- 86. Hybridization capture vs amplicon sequencing | IDT [https://www.idtdna.com/page/support-and-education/decoded-plus/targeted-sequencing-hybridization-capture-or-amplicon-sequencing/]
- 87. Targeted Sequencing Approaches for NGS [https://www.thermofisher.com/us/en/home/life-science/sequencing/sequencing-learning-center/next-generation-sequencing-information/ngs-basics/targeted-sequencing-approaches.html]
- 88. Evaluation of Hybridization Capture Versus Amplicon‐ ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC4832303/]
- 89. Target Enrichment | NGS-based hybrid capture method [https://www.illumina.com/techniques/sequencing/dna-sequencing/targeted-resequencing/target-enrichment.html]
- 90. A Feasibility Study of NGS-Based Variant Analysis of FFPE ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12384127/]
- 91. Effect of decalcification protocols on immunohistochemistry ... [https://www.sciencedirect.com/science/article/pii/S0893395222007931]
- 92. Maximizing DNA Yield and Integrity from Limited FFPE ... [https://scholarworks.utrgv.edu/somrs/2025/posters/150/]
- 93. Rapid detection of EGFR mutations in decalcified lung ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC6962695/]
- 94. Validation of a comprehensive long-read sequencing ... [https://www.frontiersin.org/journals/genetics/articles/10.3389/fgene.2025.1499456/full]
- 95. Validation of the NovaSeq6000 Platform and automated ... [https://www.sciencedirect.com/science/article/pii/S2001037025004556]
- 96. Determination of high-confidence germline genetic variants ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12326712/]
- 97. AmpliSeq™ for Illumina® Direct FFPE DNA [https://www.govsci.com/product-detail/Illumina-----Inc/20023378/EA/?srsltid=AfmBOopi_uXjdXkH1-Ky8Z7mKtou-St3ThqDKsBE-UcBDFhpQhKCr-EK]
- 98. Ultima Genomics UG 100 platform vs. Illumina NovaSeq X ... [https://www.illumina.com/science/genomics-research/articles/ultima-ug-100-vs-illumina-novaseq-x-wgs-data.html]